深度学习-1-基础知识
本文最后更新于:2021年7月31日 晚上
创作声明:主要为李宏毅老师的听课笔记,附视频链接:https://www.bilibili.com/video/BV1Wv411h7kN?p=2
机器学习
提到深度学习(Deep Learning),不得不先提到机器学习(Machine Learning)。
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
我个人认为,当下的机器学习可以概述成一句话,
机器学习就是让计算机具备找函数的问题
举例而言:
语音辨识,向计算机输入一段声音,产生这段声音对应的文字,那你需要的就是一个函数,这个函数的输入是声音讯号,输出是这段声音讯号的属性。这个函数非常复杂,人类没有能力把它写出来,所以我们期待凭借着计算机,把这个函数找出来,这件事情,就是机器学习。
机器学习的任务
我们要找的函数不同,机器学习有不同的类别,简单举几个常用:
- Regression
Regreesion(回归),输出是一个 scalar(标量)。举个例子:
预测未来某一个时间的PM2.5的数值,计算机做的事情是找一个函数,这个函数的输出,是明天中午的PM2.5的数值,的输入可能是种种跟预测PM2.5有关的指数,包括今天的PM2.5的数值,今天的平均温度,今天平均的臭氧浓度等等,这一个函数可以拿这些数值当作输入,输出明天中午的PM2.5的数值,那这一个找这个函数的任务,叫作 Regression。
- Classification
Classification(分类),输出的是给定选项中的某个选项。举个例子:
每个人都有邮箱,那邮箱里面有一个函数,这个函数可以帮我们侦测一封邮件,是不是垃圾邮件,在侦测垃圾邮件这个问题里面,可能的选项就是两个,是垃圾邮件或不是垃圾邮件,Yes或者是No,输出一个选项,寻找这样一个函数的问题叫作 Classification,Classification 不一定只有两个选项,也可以有多个选项。
- Structured Learning
Structured Learning(结构化学习),输出是一个有结构的事物,举例而言。计算机画一张图,写一篇文章。
从机器学习案例开始了解
问题描述
根据一个频道过往所有的信息去预测它明天有可能的观看的次数是多少,就是找一个函数,这个函数的输入是这个频道过去的信息,输出就是第二天这个频道的观看的次数。
解决步骤
1.Function with Unknown Parameters
第一步,我们先做一个最初步的猜测,比如:$y=b+w*x_1$
- $y$是我们要预测的数值
- $x_1$是这个频道前一天总共观看的次数,$x_1$在这里是数值
- $b$和$w$都是未知的参数,我们并不知道
这个猜测来自于你对这个问题本质上的了解,就是 Domain knowledge(领域知识)。
关于$y=b+w*x_1$,$b$和$w$都是未知的 Parameters(参数)
而这个带有 Unknown Parameters 的 Function(函数)我们就叫做 model(模型),model在机器学习里面,就是一个带有未知的 Parameter 的 Function。
$w$:weight(权重)
$x_1$:Feature(特征)
$b$:bias(偏差)
2.Define loss from Training Data
第二步,我们定义一个东西叫做 loss,
Loss is a Function of parameters. $L(b,w)$
loss:how good a set of values are.
Loss Function(损失函数),它的输入,是我们 model 里面的参数(b和w),输出的值代表我们把这一组未知的参数,设定成某一组数值的时候,这组数值好还是不好。
计算 loss 要从训练数据出发,在这个问题里面,我们的训练数据是这一个频道过去每天的观看次数,假设此时b设为0.5k,w设为1的时候,我们把2017年1月1号的观看次数代入x1,结果是5.3k,我们是知道1月2号的真实值,所以我们可以比较一下,现在这个函数预估的结果跟真正的结果的差距有多大,这个函数预估的结果是5.3k,真正的结果是4.9k,那这个真实的值叫做 Label(标签) ,估测的值用y来表示,真实的值用ŷ来表示,你可以计算y跟ŷ之间的差距,得到一个eₗ,代表估测的值跟真实的值之间的差距,计算差距其实不只一种方式,这边把y跟ŷ相减,直接取绝对值,算出来的值是0.4k。
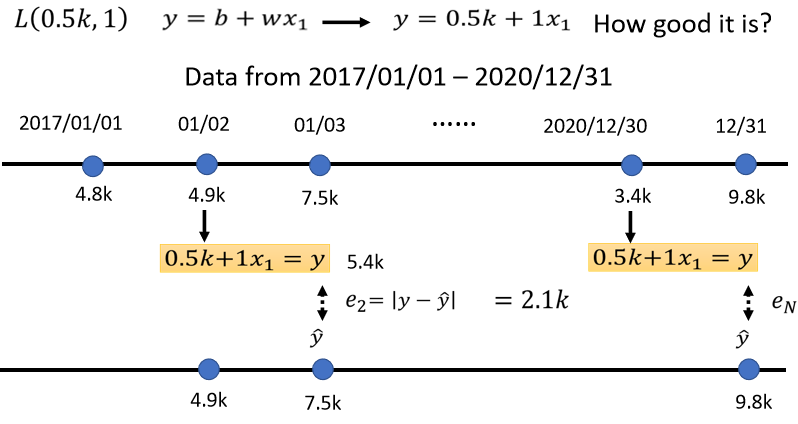
同一个方法,可以算出这三年来每一天的预测的误差,假设我们今天的 Function,是$y=0.5k+1*x_1$,这三年来每一天的误差都可以算出来,每一天的误差都可以给我们一个小e,接下来我们就把每一天的误差加起来然后取得平均,N代表我们的训验数据的个数,对于三年来的训练数据,每年365天,所以365乘以3,那我们算出一个L,我们算出一个L,这L是每一笔训练数据的平均误差,在这里这个L就是我们的 loss。
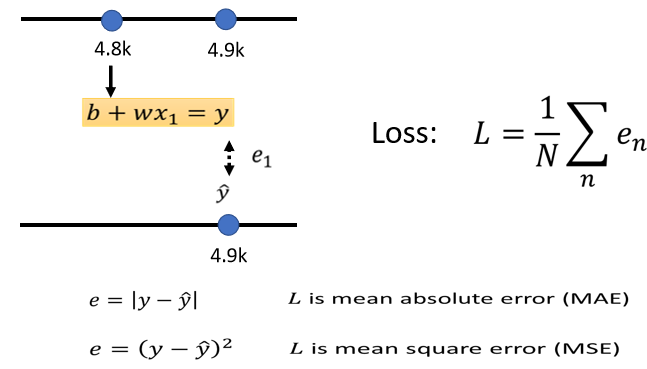
L越大,代表我们现在这一组参数越不好,这个L越小,代表现在这一组参数越好。
估测的值跟实际的值之间的差距,其实有不同的计算方法,在我们刚才的例子里,我们是算y跟ŷ之间绝对值的差距,这一种计算差距的方法,得到的这个L,得到的 loss 叫 mean absolute error,缩写是 MAE,如果你今天的e是用y跟ŷ相减的平方算出来的,这个叫mean square error,又叫 MSE,我们选择 MAE,作为我们计算这个误差的方式,把所有的误差加起来,就得到 loss,那你要选择 MSE 也是可以的,有一些任务,如果y和ŷ它都是概率,都是概率分布的话,在这个时候,你可能会选择Cross-entropy,这个我们之后再说,我们这边就是选择了MAE,那这个是机器学习的第二步。
补充:
Error Surface(误差曲面)
我们可以调整不同的w和不同的b,组合起来以后为不同的w跟b的组合计算它的 loss,然后就可以画出以下这一个等高线图,这个等高线图就叫Error Surface。
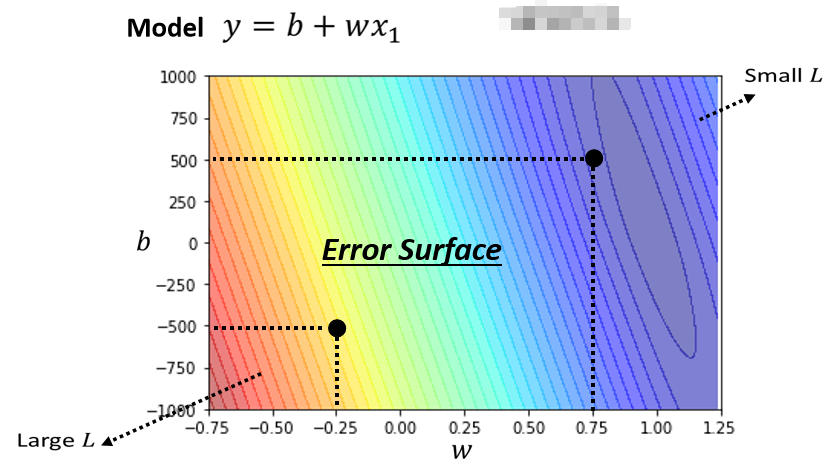
在这个等高线图上面,越偏红色系,代表计算出来的 loss 越大,就代表这一组参数越差,如果越偏蓝色系,就代表 loss越小,就代表这一组参数越好。
3.Optimization
第三步,要做的事情其实是解一个最优化的问题,英文也叫Optimization(最优化),对于这个案例,我们要做的事情就是,找一组w跟b的数值出来使我们的 loss 的值最小。
一种常用的Optimization的方法,叫做 Gradient Descent(梯度下降)。 简化起见,我们先假设没有b那个未知的参数,只有w这个未知的参数.
Gradient Descent的步骤
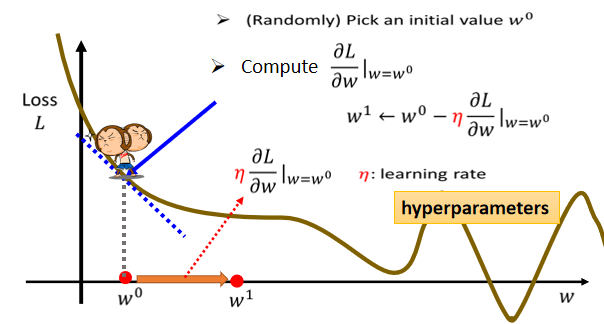
- 随机选取一个初始的点,我们叫做w0,这个初始的点往往真的就是随机的,其实有一些方法可以给我们一个比较好的w0的值,我们先当作都是随机的。
- 计算在w=w0的时候,w这个参数对 loss 的微分是多少,也就是计算在这一个点 Error Surface 的切线斜率,也就是这一条蓝色的虚线,如果这一条虚线的斜率是负的代表说在这个位置左边比较高,右边比较低。
- 左边比较高右边比较低的话,我们就把w的值变大,那我们就可以让 loss 变小,如果算出来的斜率是正的,就代表说左边比较低右边比较高,我们把w变小了,w往左边移,可以让 loss 的值变小,可以想像说有一个人站在这个地方下山,然后他左右环视一下,那这一个算微分这件事啊,就是左右环视,它会知道左边比较高还是右边比较高,看哪边比较低,它就往比较低的地方跨出一步,那这一步的步伐的大小取决于两件事情。
- 第一件事情是这个地方的斜率有多大,这个地方的斜率大,这个步伐就跨的大一点,斜率小步伐就跨的小一点。
- 除了斜率以外,就是除了微分这一项,还有另外一个东西会影响步伐大小,叫做 learning rate(学习速率),它是你自己设定的,你自己决定这个的大小,如果设大一点,那你每次参数 Update(更新) 就会量大,你的学习可能就比较快,如果η设小一点,那你参数的 Update 就很慢,每次只会改变一点点参数的数值,这种在机器学习需要自己设定的东西,叫做HyperParameters(超参数)。
补充:loss 可以是负的吗?
loss 这个函数是自己定义的,如果 loss 的定义,就跟刚才定的一样是绝对值,那它就不可能是负值,但这个 loss,这个 Function 是你自己决定的,所以它有可能是负的。
我们说我们要把w⁰往右移一步,那这个新的位置就叫做w¹,这一步的步伐是η乘上微分的结果,如果用数学式来表示它的话,就是把w⁰减掉η乘上微分的结果,得到w¹,如图所示。
Gradient Descent 什么时候会停下来
- 第一种状况是你失去耐心了,你一开始会设定说,我今天在调整我的参数的时候,我在计算我的微分的时候,我最多计算几次,比如设定100万次,那参数更新100万次以后就不再更新了,至于要更新几次,这个也是一个 HyperParameter,由自己决定的。
- 理想上的停下来的可能是,我们不断调整参数,调整到一个地方,它的微分的值算出来正好是0的时候,如果这一项正好算出来是0,0乘上 learning rate η 还是0,所以你的参数就不会再移动位置,那假设我们是这个理想的状况,我们把w⁰更新到w¹,再更新到w²,最后更新到wᵗ,wᵗ卡住了,也就是算出来这个微分的值是0了,那参数的位置就不会再更新。

Gradient Descent 这个方法,有一个严重的问题,我们很可能没有找到真正最好的解,我们没有找到那个可以让 loss 最小的那个w,在这个例子里面,把w设定在右侧红点附近这个地方,你可以让 loss 最小,但是如果 Gradient Descent,是从w⁰这个地方当作随机初始的位置的话,很有可能走到wᵗ这里,你的训练就停住了,你就没有办法再移动w的位置。
那右侧红点这一个位置,这个真的可以让 loss 最小的地方,叫做 global minima(全局最小值),而wᵗ这个地方叫做 local minima(局部最小值),它的左右两边,都比这个地方的 loss 还要高一点,但是它不是整个 Error Surface 上面的最低点。
补充: 常常可能会听到有人讲到,Gradient Descent 不是个好方法,这个方法会有 local minima 的问题,没有办法真的找到 global minima,事实上,假设你有做过深度学习相关的事情,假设你有自己训练 network ,自己做过 Gradient Descent 经验的话,我们在做 Gradient Descent 的时候,真正面对的难题不是 local minima,到底是什么之后再说。
实际上我们刚才的模型有两个参数,有w跟b,那有两个参数的情况下,怎么用 Gradient Descent 呢,其实跟刚才一个参数没有什么不同,若一个参数你没有问题的话,你可以很快的推广到两个参数。

实际上真的用 Gradient Descent,对数据进行一番计算以后我们算出来的最好的w是0.97,最好的b是0.1k,跟我们的猜测蛮接近的,那 loss 多大呢,loss 算一下是0.48k,也就是在2017到2020年的数据上,如果使用这一个函数,b代入0.1k,w代入0.97,那平均的误差是0.48k,也就是它的预测的误差,大概是500次左右。
Linear Model
Linear Model(线性模型) 实际上,以上三个步骤我们合起来叫做模型的训练。
我们接下来要做的事情就是拿这个函数,来真的预测一下未来的观看次数,那这边,我们只有2017年到2020年的值,我们在2020年的最后一天,跨年夜的时候,找出了这个函数,接下来从2021年开始每一天,我们都拿这个函数,去预测隔天的观看人次,我们就拿2020年的12月31号的,观看人次,去预测2021年元旦的观看人次,用2021年元旦的观看人次,预测一下2021年元旦隔天,1月2号的观看人次,用1月2号的观看人次去预测,1月3号的观看人次,每天都做这件事,一直做到2月14号,就做到情人节,然后得到平均的值,平均的误差值是多少呢,这个是真实的数据的结果,在2021年没有看过的数据上,这个误差值是,我们这边用 L prime 来表示,它是0.58,所以在有看过的数据上,在训练数据上,误差值是比较小的,在没有看过的数据上,在2021年的数据上,看起来误差值是比较大的,那我们每一天的平均误差,有600人左右。
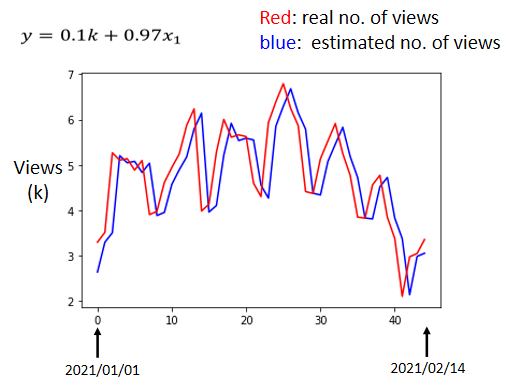
分析结果(后期修改)
- 横轴代表时间
- 纵轴代表观看次数
- 红线为真实次数
- 蓝线为预测次数
这蓝色的线没什么神奇的地方,基本就是红色的线往右平移一天而已,计算机就是拿前一天的观看人次来预测第二天的观看人次,但是如果你仔细观察这个图,你就会发现,这个真实的数据有一个很神奇的现象,它是有周期性的,我们看真实的数据,每隔七天一个循环,每个礼拜五礼拜六,看的人就是特别少。所以既然我们已经知道每隔七天,就是一个循环,那这一个model,显然很烂,因为它只能够看前一天。
每隔七天它一个循环,如果我们一个模型,它是参考前七天的数据,把七天前的数据,直接复制到拿来当作预测的结果,也许预测的会更准也说不定,所以我们就要修改一下我们的模型,通常一个模型的修改,往往来自于你对这个问题的理解,也就是 Domain Knowledge。
一开始,我们对问题完全不理解的时候,我们就胡乱写一个并没有做得特别好,接下来我们观察了真实的数据以后,得到一个结论是每隔七天有一个循环,所以我们应该要把前七天的观看人次都列入考虑,所以我们写了一个新的模型。
xⱼ下标j代表是几天前,然后这个j等于1到7,也就是从一天前两天前,一直考虑到七天前,乘上不同的wⱼ,加起来,再加上 bias,得到预测的结果。
如果这个是我们的 model,那我们得到的结果是怎么样呢,我们在训练数据上的 loss 是0.38k,那因为这边只考虑一天,这边考虑七天,所以在训练数据上,你会得到比较低的 loss,这边考虑了比较多的信息,在训练数据上理论应该要得到更好的,更低的 loss,这边算出来是0.38k,但它在没有看过的数据上面,做不做得好呢,在没有看到的数据上确实有比较好,是0.49k,只考虑一天是0.58k的误差,考虑七天是0.49k的误差。
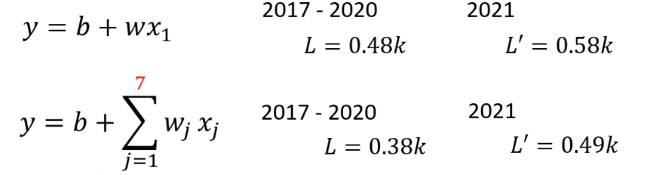
然后考虑28天会怎么样呢,预测出来结果在训练数据上是0.33k,那在2021年的数据上,在没有看过的数据上是0.46k,看起来又更好一点,那接下来考虑56天会怎么样呢,在训练数据上是稍微再好一点,是0.32k,在没看过的数据上还是0.46k,看起来,考虑更多天没有办法再更进步了,看来考虑天数这件事,也许已经到了一个极限,这些模型,它们都是把输入的这个x,它叫做 Feature,把 Feature 乘上一个 weight,再加上一个bias就得到预测的结果,这样的模型有一个共同的名字,叫做 Linear model,那我们接下来会看,怎么把 Linear model做得更好。
Linear Model 过于简单只能描述简单的线性关系,我们需要更复杂的 model,
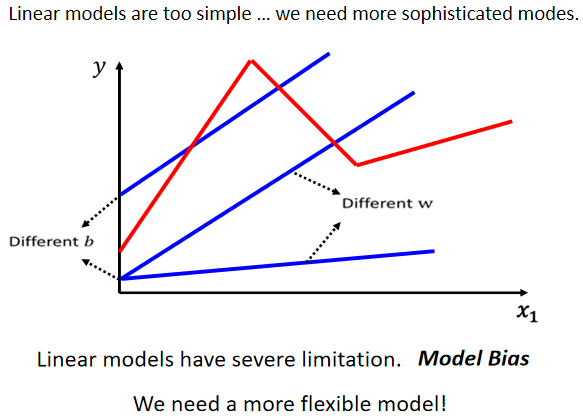
你不管怎么改变w跟b,你永远无法用 Linear Model,制造红色这一条线,显然LinearModel有很大的限制,这一种来自于Model的限制,叫做 Model Bias(模型偏差),跟b的这个Bias不太一样,它指的意思是说,模型先天限制没有办法模拟真实的状况。
深度学习
从更好的Function的开始
我们需要写一个更复杂的,更有弹性的,有未知参数的 Function,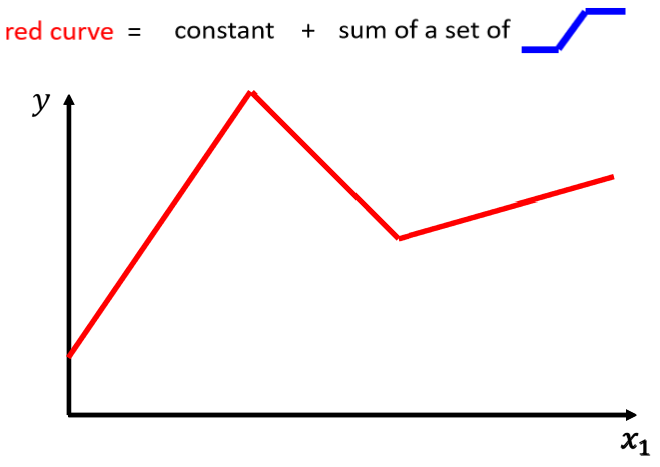
观察一下红色的这一条曲线,它可以看作是一个常数,再加上一群蓝色的这样子的 Function。
蓝色的 Function,它的特性是:
- 当输入的值,当x轴的值小于某一个数的时候,它是某一个定值。
- 大于另外一个数的时候,又是另外一个定值。
- 中间有一个斜坡。
红色的线可以看作是一个常数项加一大堆的蓝线,常数项应该设跟y轴的交点一样。如何怎么加上这个蓝色的 Function 以后,变成红色的这一条线。
以本图为例子:
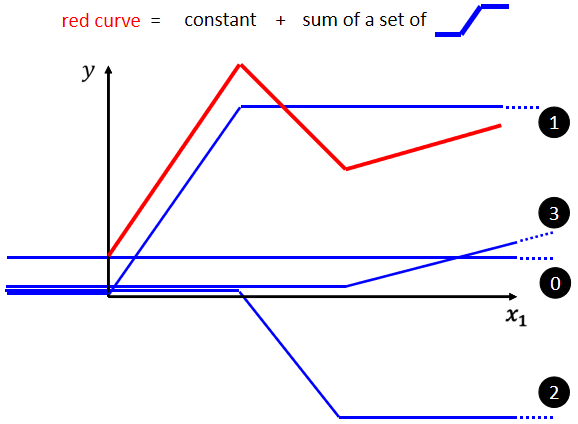
蓝线“1” Function 斜坡的起点,设在红色 Function 的起始的地方,然后第二个斜坡的终点设在第一个转角处,你刻意让这边这个蓝色 Function 的斜坡,跟这个红色 Function 的斜坡,它们的斜率是一样的,然后接下来,再加第二个蓝色的 Function,你就看红色这个线,第二个转折点出现在哪里,所以第二个蓝色 Function,它的斜坡就在红色 Function 的第一个转折点,到第二个转折点之间,你刻意让这边的斜率跟这边的斜率一样
然后接下来第三个部分,第二个转折点之后的部分,你就加第三个蓝色的 Function,第三个蓝色的 Function,它这个坡度的起始点,故意设的跟这个转折点一样,这边的斜率,故意设的跟这边的斜率一样,好接下来你把0,1,2,3全部加起来,你就得到红色的这个线。
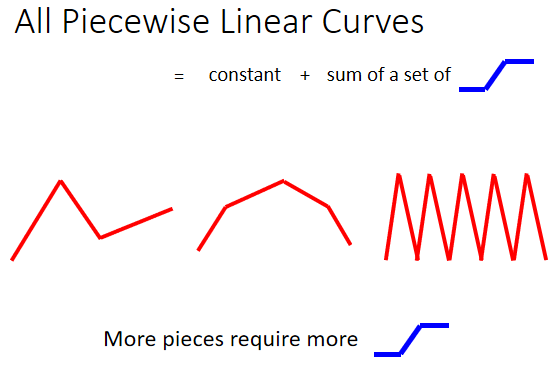
上图的 Curves(曲线) ,由很多线段所组成的,这个叫做 Piecewise Linear(分段线性) 的 Curves,这些 Piecewise Linear 的 Curves,有办法用常数项,加一大堆的蓝色 Function 组合出来。只是如果 Piecewise Linear 的 Curves 越复杂,就是转折的点越多,那你需要的这个蓝色的 Function 就越多。
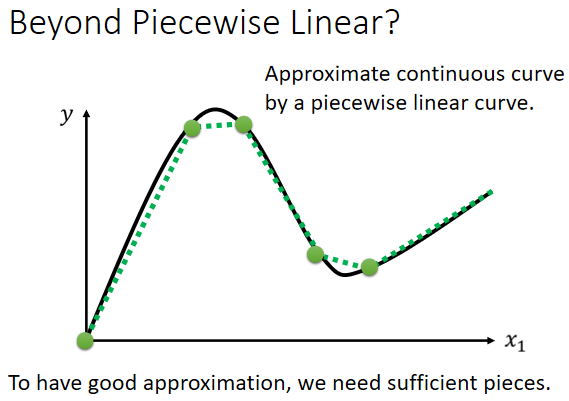
很容易由以直代曲的思想得出结论,可以用 Piecewise Linear 的 Curves,去逼近任何的连续的曲线,而每一个 Piecewise Linear 的 Curves,又都可以用一大堆蓝色的 Function 组合起来,也就是说,只要有足够的蓝色 Function 把它加起来,就可以变成任何连续的曲线。
蓝色的 Function,它的式子如何表示呢。
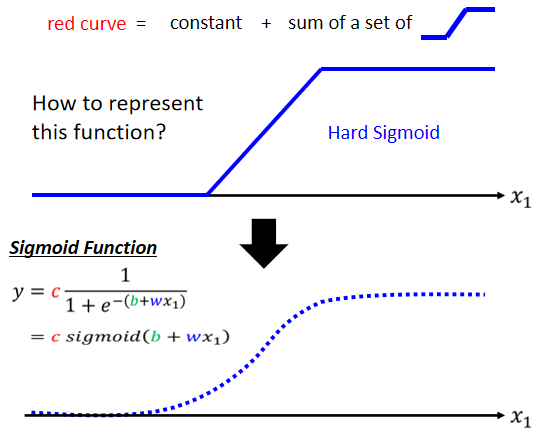
我们用Sigmoid Function去逼近这个蓝色的 Function,那这个蓝色的 Function,其实通常就叫做Hard Sigmoid,Sigmoid Function是 S 型的 Function,
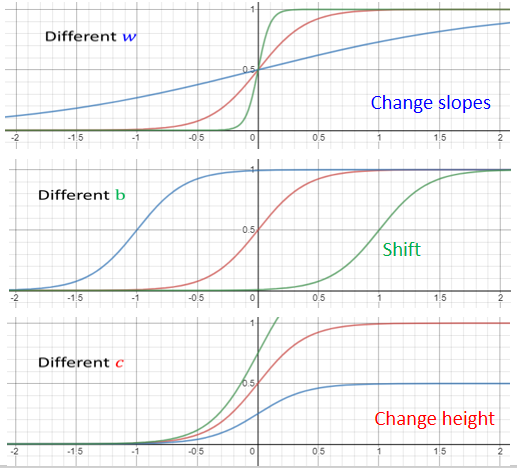
调整这里的b跟w跟c,你就可以制造各种不同形状的Sigmoid Function,用各种不同形状的Sigmoid Function,去逼近这个蓝色的Function。
- 改w你就会改变斜率你就会改变斜坡的坡度
- 改b你就可以把这一个 Sigmoid Function 左右移动
- 改c你就可以改变它的高度
总结:你只要有不同的w不同的b不同的c,你就可以制造出不同的 Sigmoid Function,把不同的 Sigmoid Function 叠起来以后,你就可以去逼近各种不同的Piecewise Linear的 Function,然后Piecewise Linear的 Function,可以拿来近似各种不同的连续的 Function。
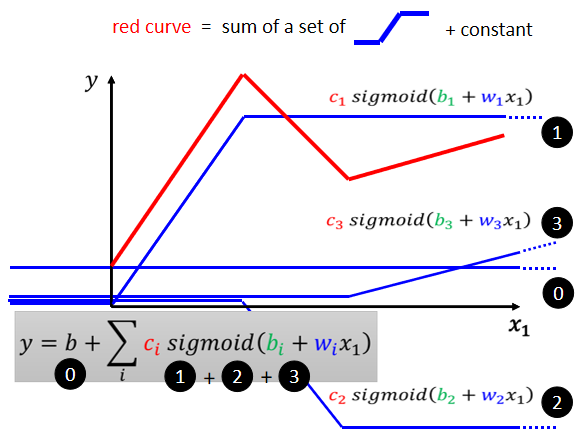
红色这条线就是0加1+2+3,123都是蓝色的 Function,所以它们的函数就是有一个固定的样子,但是它们的w不一样,它们的b不一样,它们的c不一样,如果是第一个蓝色 Function,它就是w1,b1,c1,第二个蓝色 Function,用的是w2,b2,c2,第三个蓝色 Function,我们就说它用的是w3,b3,c3。
我们刚才其实已经不是只用一个 Feature,我们可以用多个 Feature。用j表示 Feature 编号,很容易写出来式子,如图。

从线性代数来看 Function
假设只考虑三个 Feature,等于1 2 3,那所以输入就是x1代表前一天的观看人数,x2两天前观看人数,x3三天前的观看人数
每一个i就代表了一个蓝色的 Function,而我们现在每一个蓝色的 Function,都用一个 Sigmoid Function 来逼近它。
这个1,2,3就代表我们有三个 Sigmoid Function,那我们先来看一下,这个括号里面做的事情如图:
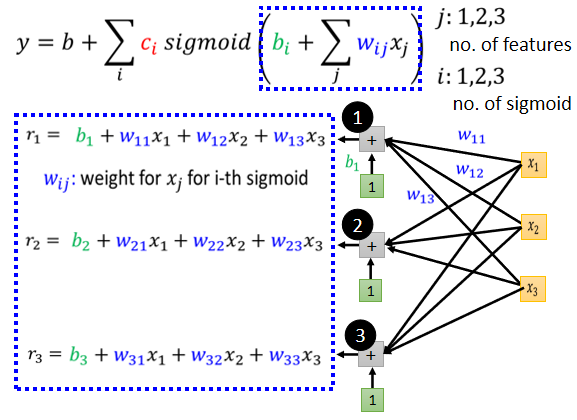
简化起见,我们把括号里面的东西用r1,r2,r3表示:
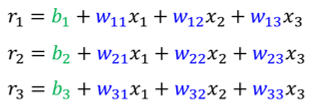
由线性代数知识简化成矩阵跟向量的相乘,并可以改换表示形式成:x乘上矩阵w再加上向量 b,得到一个向量叫做r。

在这个括号里面做的事情就是这么一回事,把x乘上w加上b等于r,就是这边的r1,r2,r3,这是r1,r2,r3,然后分别通过 Sigmoid Function 得到a1,a2,a3,所以下图这个蓝色的虚线里面做的事情,就是从x1,x2,x3得到了a1,a2,a3。
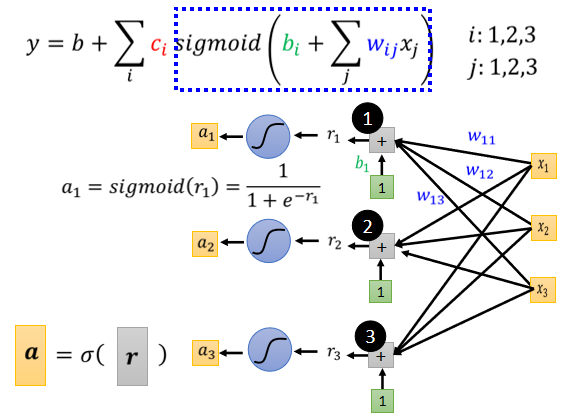
这个 Sigmoid 的输出,还要乘上ci然后还要再加上b,如果你要用向量来表示的话,a1,a2,a3拼起来叫这个向量a,c1,c2,c3拼起来叫一个向量c,那我们可以把这个c呢,作Transpose(转置),a乘上c的 Transpose 再加上b,我们就得到了y,于是可以继续简化:
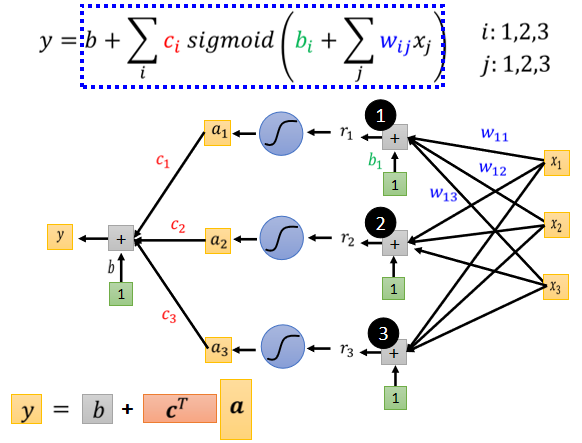
最终的线性代数式子:
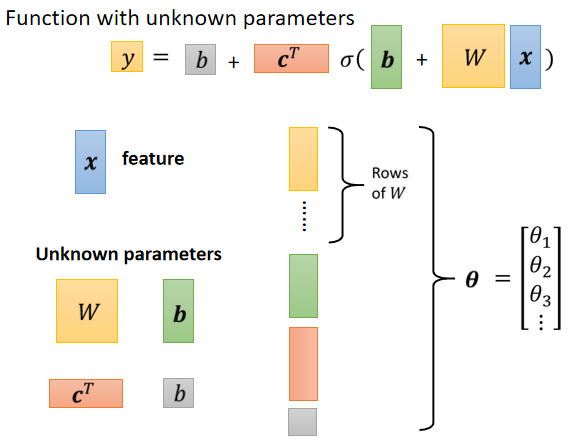
补充解释:
灰色b是数值,绿色是向量,表示他们不同。
将b,b,w的每一个 row 或者 column 拿出来,还有 c拼成一个很长的向量$\theta$,$\theta$统称我们所有的未知的参数。
loss
loss 没有什么不同,定义的方法是一样的,只是我们的符号改了一下,之前是$L(w,b)$,因为w跟b是未知的,那我们现在接下来的未知的参数很多了,所以我们直接用$\theta$来统设所有的参数,所以我们现在的 loss Function 就变成$L(\theta)$
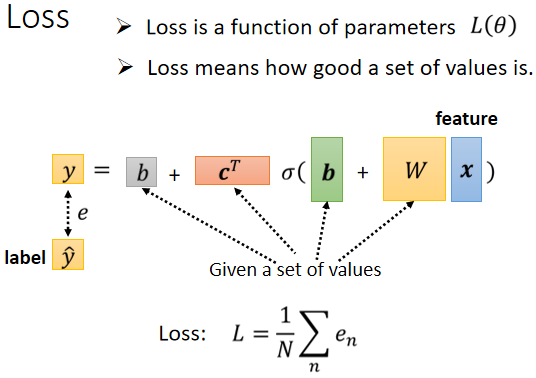
计算的方法跟刚才只有两个参数的时候一样,给定一组$\theta$的值,代入一组 Feature,将估测值与真实label比较得到误差,重复带入不同组 Feature,将得到的所有误差处理得到 loss。
Optimization
Optimization 也是一样的,Optimization 的步骤本质没有区别:


补充知识
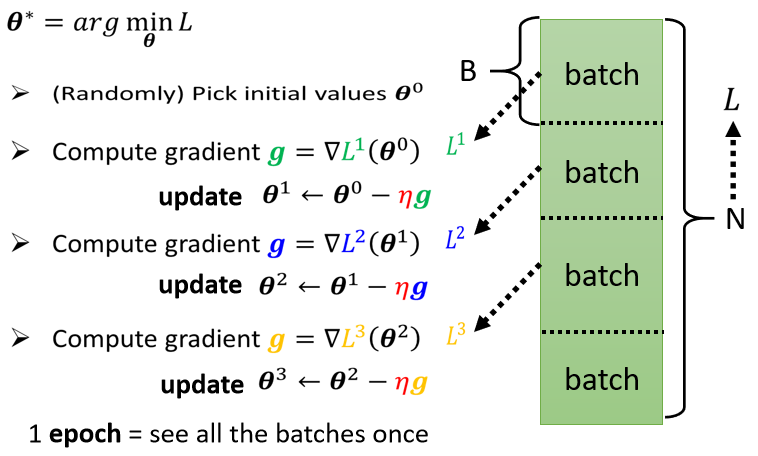
Batch&&Epoch
实际上我们在做Gradient Descent的时候,我们会这么做,比如我们这边有N个数据,我们会把N个数据随机分成一个一个的Batch(批),每个 Batch 里面有B个数据。
本来我们是把所有的 Data 拿出来算一个 Loss,现在我们只拿一个 Batch 里面的 Data 出来算一个 Loss,我们这边把它叫L1,那跟L以示区别,因为你把全部的数据拿出来算 Loss,跟只拿一个 Batch 的数据拿出来算 Loss 不一样,所以这边用L1来表示它。
实际操作的时候,每次我们会先选一个 Batch,用这个 Batch 来算L,根据这个L1来算 Gradient,用这个 Gradient 来更新参数,接下来再选下一个 Batch 算出L2,根据L2算出Gradient,然后再更新参数,再取下一个 Batch 算出L3,根据L3算出 Gradient,再用L3算出来的 Gradient 来更新参数,把所有的 Batch 都看过一次,叫做一个 Epoch(时期),每一次更新参数叫做一次 Update, Update 跟 Epoch 并不一样。
两个例子:
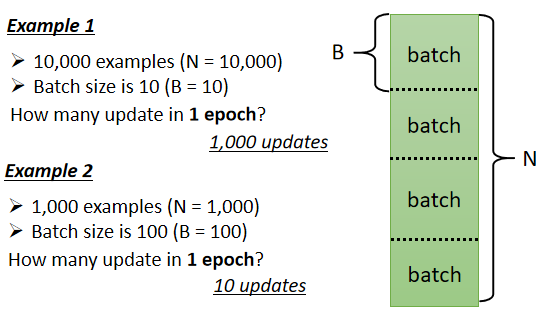
假设有1000对数据,Batch Size(批尺寸) 设100,Batch Size 的大小是你自己决定的,所以这边我们又多了一个 HyperParameter,1000个 Example,Batch Size 设100,那1个 Epoch 总共更新10次参数,所以做了一个 Epoch 的训练,更新多少次参数取决于它的 Batch Size 有多大。
ReLU
Hard Sigmoid 可以看作是两个Rectified Linear Unit(线性整流函数,简称 ReLU ) 的加总,所谓 Rectified Linear Unit,如图所示:
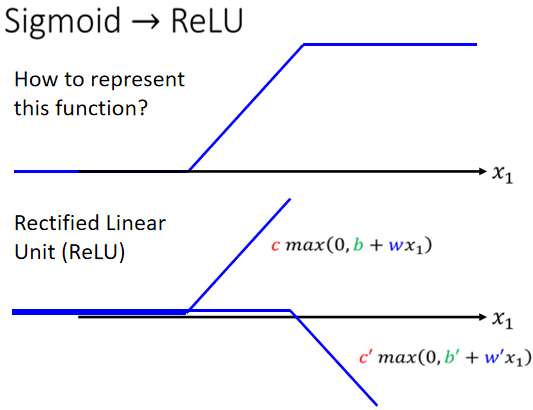
把两个 ReLU 叠起来,就可以变成 Hard 的 Sigmoid,想要用 ReLU 的话,把 Sigmoid 的地方,换成$c*max(0,b+wx_1)$。
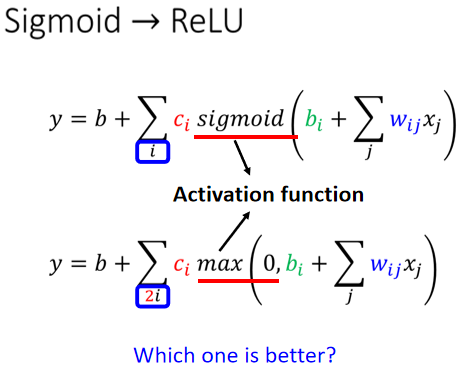
Sigmoid 或是 ReLU,它们在机器学习里面统称为 Activation Function(激活函数)。
当然还有其他的 Activation Function,但 Sigmoid 跟 ReLU,应该是今天最常见的 Activation Function。(一般 ReLU 效果比 Sigmoid 好)。
时髦的命名
那我们现在还缺了一个东西,缺一个好名字,只鞋半缕的,说他是汉左将军宜城亭侯中山靖王之后也就有排面起来了,所以我们的模型也需要一个好名字,所以它叫做什么名字呢,这些 Sigmoid 或 ReLU ,它们叫做 Neuron(神经元),我们这边有很多的Neuron,很多的Neuron就叫做 Neural Network(神经网络),Neuron就是神经元,人脑中就是有很多神经元,很多神经元串起来就是一个神经网络,跟大脑一样的,接下来你就可以到处骗麻瓜说这个模型就是在模拟人脑,这个就是人工智能,然后麻瓜就会吓得把钱掏出来。(快笑死了)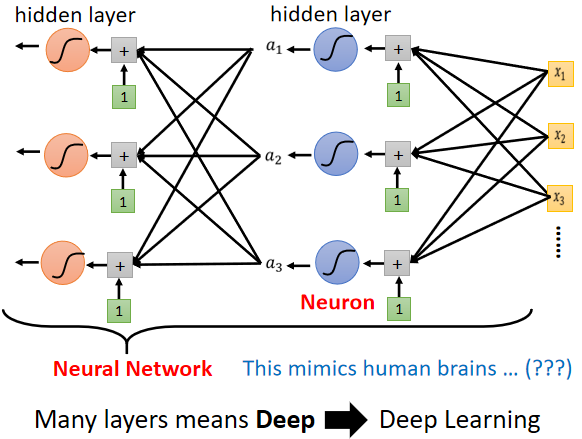
这个把戏在上个80-90年代的时候其实已经玩过了,Neural Network 不是什么新的技术,当时已经把这个技术的名字搞到臭掉了,Neural Network 因为之前吹捧得太过浮夸,所以后来大家对 Neural Network 这个名字,都非常地感冒,它就像是个脏话一样,写在 Paper 上面都注定害你的 Paper 被拒绝, 所以后来为了要重振 Neural Network,就需要新的名字,什么样的新的名字呢,这边有很多的 Neuron,每一排 Neuron 我们就叫它一个 Layer(层),它们叫 Hidden Layer(隐藏层),有很多的 Hidden Layer 就叫做 Deep,这整套技术就叫做 Deep Learning。
所以人们就开始把神经网络越叠越多越叠越深,12年的时候有一个 AlexNet,它有8层它的错误率是16.4%,两年之后VGG 19层,错误率在图像辨识上进步到7.3 %,这个都是在图像辨识基准的数据集上面的结果,后来 GoogleNe t有错误率降到6.7%,有22层,但这些都不算是什么,Residual Net有152层,但其实要训练这么深的 Network 是有诀窍的,后面再写。
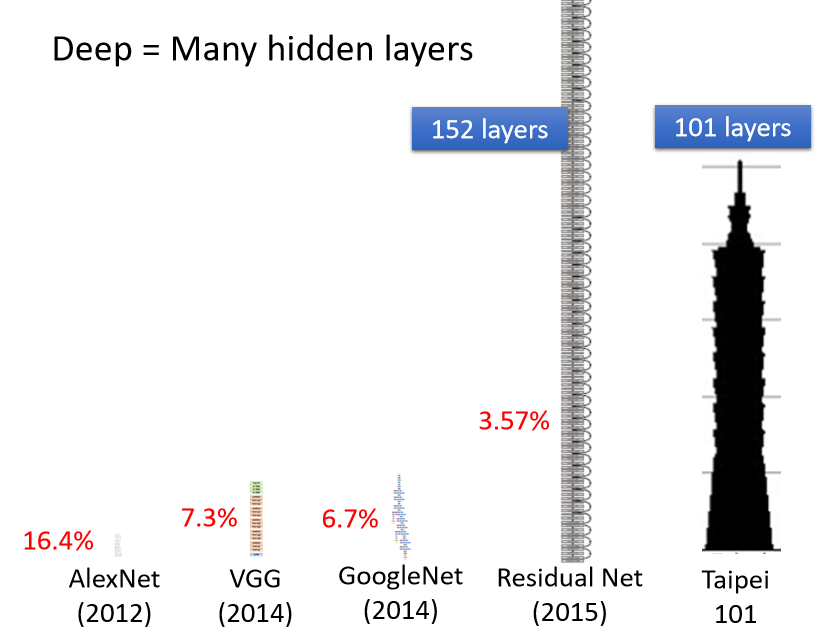
层数能一直叠下去吗?分析这个图:
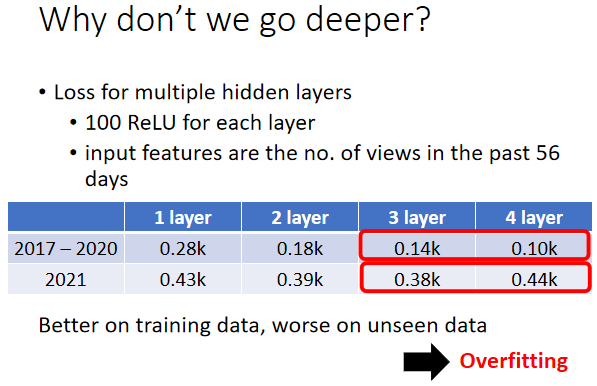
在训练数据上,3层比4层差,4层比3层好,但是在没看过的数据上,4层比较差,3层比较好,在有看过的数据上,在训练数据上,跟没看过的数据上,它的结果是不一致的,这种训练数据跟测试,这种训练数据跟没看过的数据,它的结果是不一致的状况,这个状况叫做 Overfitting(过拟合),精确的语言表述是为了得到一致假设而使假设变得过度复杂,但你目前明白它是说表现在训练好的模型在训练集上效果很好,但是在测试集上效果差即可,一般情况下过度叠加层数会导致过拟合。
一个思考:深的意义在哪里?
如果你仔细思考一下,实际上只要够多的 ReLU 够多的 Sigmoid ,就可以逼近任何的连续的Function,我们只要有够多的 Sigmoid,就可以知道够复杂的线段,就可以逼近任何的Continuous(连续) 的Function,所以我们只要一排 ReLU 或一排 Sigmoid,够多就足够了,那深的意义到底何在呢?后续的文章会给出解答。
本文尚待回答的问题(后续文章更新)
- 怎么样初始化一组较好的参数
- Cross-entropy 等损失函数是什么
- Gradient Descent 的真正难题
- 为什么ReLU效果更好
- 为什么要分成 Batch 处理
- 深的意义在哪里?
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!