深度学习-2-降低Loss上篇-Model Bias
本文最后更新于:2021年7月31日 晚上
创作声明:主要为李宏毅老师的听课笔记,附视频链接:https://www.bilibili.com/video/BV1Wv411h7kN?p=10
从一张图开始
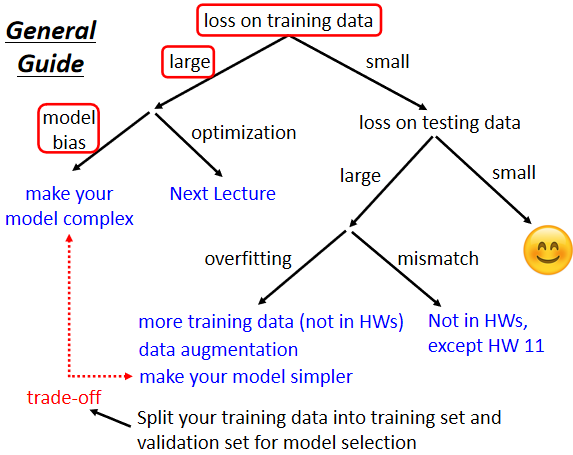
这张图十分简单易懂,指出了一个通用的降低 loss 的方法,接下来是一些补充的阐述。
Model Bias与Optimization
Model Bias
我们已经知道,假设我们的 model 过于简单,那即使我们找到了使这个模型效果最好的一组参数,它的 loss 依然很高,甚至不如别的模型相对效果很差的一组参数, 这个时候需要重新设计一个 model,给 model 更大的弹性,可以用 Deep Learning增加更多的弹性,你可以增加更多 features,总之使你的 model 更加复杂,更有弹性去描述复杂情况。
但并不是 training 时,loss大就代表一定是 Model Bias,你可能会遇到另外一个问题,这个问题是 Optimization 做得不好。
Optimization
我们经常用的gradient desecent,之前的笔记已经提到了会有 local minima 的问题。
){kind=link}
那么 training data 的 loss 不够低的时候,到底是 model bias,还是 optimization 的问题呢?一个建议是看到一个你从来没有做过的问题,可以先跑一些比较小的,比较浅的network,甚至用一些不是 deep learning 的方法,比如说 linear model,它们比较容易做Optimize的,可以让我们先有个概念说,这些简单的 model,到底可以得到什么样的 loss,如果你发现你深的model,跟浅的model比起来,深的model明明弹性比较大,但loss却没有办法比浅的model压得更低,那就代表说你的optimization有问题,需要有一些其它的方法,来把optimization这件事情做得更好。
假设你现在经过一番努力,你已经可以让你的 training data 的loss变小了,接下来你就可以来看 testing data loss,如果 testing data loss 也足够小就结束了。
如果觉得还不够小,testing data上面的loss比 training data 上的loss小很多,那可能就是真的遇到 overfitting 的问题。
Overfitting
为什么会出现Overfitting

一个极端的例子:假设根据我们的训练集,machine learning 的方法找出了一个一无是处的function,这个一无是处的function如下工作,如果今天x当做输入的时候,我们就去比对这个x,有没有出现在训练集里面,如果x有出现在训练集里面,就把它对应的ŷ当做输出,如果x没有出现在训练集里面,就输出一个随机的值。
在 training data 上面,这个一无是处的function,它的loss是0,可在 testing data 上面,它的loss会变得很大,因为它其实什么都没有预测,这是一个比较极端的例子,在一般的状况下,也有可能发生类似的事情。
这张图很好的解释了为什么会有 overfitting,
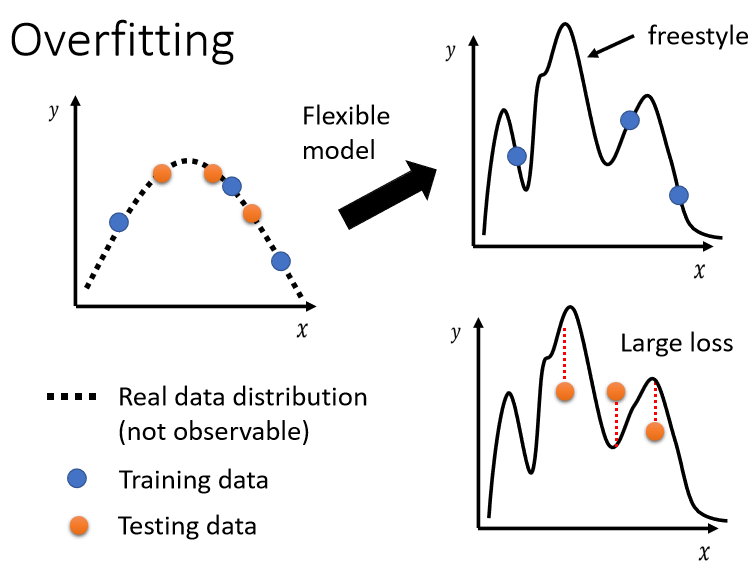
假设我们输入的feature叫做x,我们输出的level叫做y,那x跟y都是一维的,x跟y之间的关系,是这个二次的曲线,这个曲线我们刻意用虚线来表示,因为我们通常没有办法直接观察到这条曲线,们真正可以观察到的是我们的训练集,训练集你可以想像成,就是从这条曲线上面,随机sample(采样)出来的几个点。
今天的模型它的的弹性很大的话,你只给它这三个点,它会知道说,在这三个点上面我们要让loss低,所以的model的曲线会通过这三个点,但是其它没有训练集做为限制的地方,它就会有freestyle,因为它的弹性很大,所以你的model可以变成各式各样的function,产生各式各样奇怪的结果。
testing data是橙色的这些点,训练data是蓝色的这些点,用蓝色的这些点,找出一个function以后,你测试在橘色的这些点上,不一定会好,如果你的model它的自由度很大的话,它可以产生非常奇怪的曲线,导致训练集上的结果好,但是测试集上的loss很大,至于更详细的背后的数学原理,我们之后的笔记再予以探讨。
如何处理Overfitting
- 第一个方向,也许也是最有效的方向,增加你的训练集
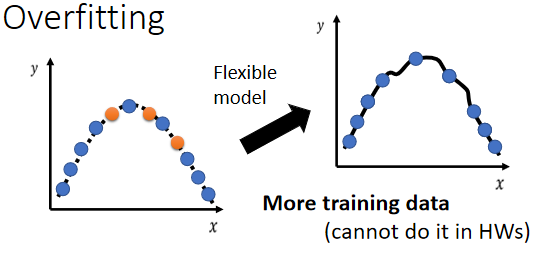
蓝色的点变多了,那虽然 model 的弹性可能很大,但是因为你这边的点非常非常的多,它就可以限制住,所以我们可以 Data Augmentation(数据集扩增) 等方法扩大训练集。
- 限制模型的弹性
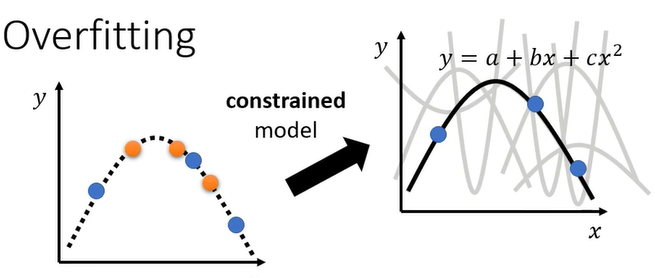
假设我们直接限制说,现在我们的 model,我们猜测出x跟y背后的关系,其实就是一条二次曲线,只是我们不明确的知道这个二次曲线里面的每一个参数长什么样,猜测的结果取决于你对这个问题的理解,如果模型就是二次曲线,那么选择function的时候就会有很大的限制,因为二次曲线来来去去就是那几个形状而已。
制造限制的方法举例来说:
- 给它比较少的参数,如果是deep learning的话,就给它比较少的神经元的数目,本来每层一千个神经元,改成一百个神经元之类的,或者让model共享参数,你可以让一些参数有一样的数值,一个例子是我们之前笔记的network的架构,叫做fully-connected network(全连接神经网络),fully-connected network 是一个比较有弹性的架构,而今天图像处理常用的CNN(全连接神经网络)是一个比较有限制的架构,CNN是一种比较没有弹性的model,它厉害的地方就是,它是针对图像的特性,来限制模型的弹性,关于CNN,之后的笔记会详谈。
- 用比较少的features。
- Early stopping(早停)
- Regularization(正则化)
- Dropout
后三者,之后的笔记会单独阐述。
但模型也不能给太多限制,限制太大就有了 model bias 过大的问题。
观察下图:
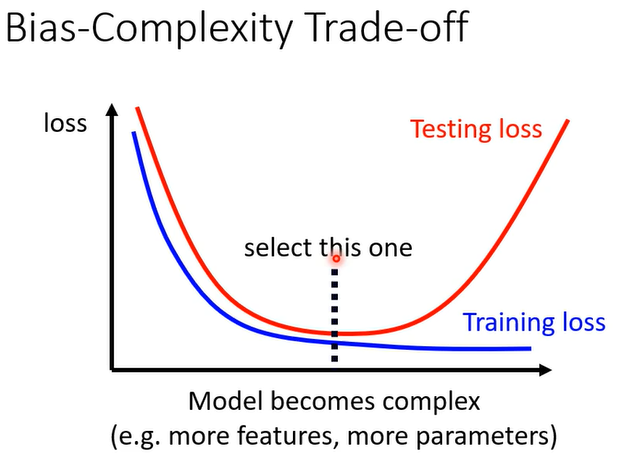
随着model越来越复杂,Training的loss可以越来越低,但是testing的时候呢,当model越来越复杂的时候,刚开始testing的loss会跟着下降,但是当复杂的程度,超过某一个程度以后,Testing的loss就会突然暴增了。
这是因为说当model越来越复杂的时候,复杂到某一个程度,overfitting的状况就会出现,那我们当然期待说,我们可以选一个中庸的模型,不是太复杂的也不是太简单的,给我们最低的testing loss,那如何选出这样的model?
以下的讨论:限于不采用精心设计的数据集(那个直接用testing set衡量即可)
下面的讨论适用于只有一个数据集(类似比赛)
可能很直觉的做法就是说:
假设我们有三个模型,它们的复杂的程度不一样,我不知道要选哪一个模型才会刚刚好,那直接用 testing set 去看哪个效果最好。
我们引入一个概念 Cross Validation(交叉验证)。
Cross Validation
交叉验证(Cross validation),交叉验证用于防止模型过于复杂而引起的过拟合.有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法。于是可以先在一个子集上做分析, 而其它子集则用来做后续对此分析的确认及验证。 一开始的子集被称为训练集。而其它的子集则被称为验证集或测试集。交叉验证是一种评估统计分析、机器学习算法对独立于训练数据的数据集的泛化能力(generalize)。(注,主要用来评估 model bias,使人们可以选择适当复杂度的模型)
留出法(holdout cross validation)
最简单的交叉验证:
在机器学习任务中,拿到数据后,我们首先会将原始数据集分为三部分:训练集、验证集和测试集。
训练集用于训练模型,验证集用于模型的参数选择配置,测试集对于模型来说是未知数据,用于评估模型的泛化能力。
这个方法操作简单,只需随机把原始数据分为三组即可。
不过如果只做一次分割,它对训练集、验证集和测试集的样本数比例,还有分割后数据的分布是否和原始数据集的分布相同等因素比较敏感,
不同的划分会得到不同的最优模型,
而且分成三个集合后,用于训练的数据更少了。
k 折交叉验证(k-fold cross validation)
k 折交叉验证通过对 k 个不同分组训练的结果进行平均来减少方差,因此模型的性能对数据的划分就不那么敏感。
第一步,不重复抽样将原始数据随机分为 k 份。
第二步,每一次挑选其中 1 份作为测试集,剩余 k-1 份作为训练集用于模型训练。
第三步,重复第二步 k 次,这样每个子集都有一次机会作为测试集,其余机会作为训练集。在每个训练集上训练后得到一个模型,用这个模型在相应的测试集上测试,计算并保存模型的评估指标。
第四步,计算 k 组测试结果的平均值作为模型精度的估计,并作为当前 k 折交叉验证下模型的性能指标。k 一般取 10,数据量小的时候,k 可以设大一点,这样训练集占整体比例就比较大,不过同时训练的模型个数也增多。数据量大的时候,k 可以设小一点。
留一法(Leave one out cross validation) LOOCV
当 k=m 即样本总数时,叫做 留一法(Leave one out cross validation),每次的测试集都只有一个样本,要进行 m 次训练和预测。
这个方法用于训练的数据只比整体数据集少了一个样本,因此最接近原始样本的分布。但是训练复杂度增加了,因为模型的数量与原始数据样本数量相同。一般在数据缺乏时使用。样本数很多的话,这种方法开销很大。
此外:多次 k 折交叉验证再求均值,例如:10 次 10 折交叉验证,以求更精确一点。划分时有多种方法,例如对非平衡数据可以用分层采样,就是在每一份子集中都保持和原始数据集相同的类别比例。模型训练过程的所有步骤,包括模型选择,特征选择等都是在单个折叠 fold 中独立执行的。
本文尚待回答的问题(后续文章更新)
- Overfitting的数学原理
- CNN的相关知识
- Early stopping,Regularization,Dropout的相关知识
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!