深度学习-8-Transformer
本文最后更新于:2021年8月5日 上午
创作声明:主要为李宏毅老师的听课笔记,附视频链接:https://www.bilibili.com/video/BV1Wv411h7kN?p=34
Sequence-to-sequence (Seq2seq)
Transformer就是一个Sequence-to-sequence的model,它的缩写我们会写做Seq2seq,那Sequence-to-sequence的model,又是什么呢?
我们之前在提到input a sequence的时候,我们说input是一个sequence,那output有三种可能,由机器自己决定output的长度就是Seq2seq。
机器翻译是一个典型的seq2seq任务,

让机器读一个语言的句子,输出另外一个语言的句子,在做机器翻译的时候,输入的文字的长度是N,输出的句子的长度是N’,N’的长度要由机器自己来决定。
除此之外,语音识别,语音合成,聊天机器人甚至文法剖析,multi-label classification都可以用Seq2Seq model的问题解决。
一般的seq2seq’s model,它里面会分成两块,一块是Encoder,另外一块是Decoder。
input一个sequence有Encoder,负责处理这个sequence,再把处理好的结果丢给Decoder,由Decoder决定,它要输出什么样的sequence,等一下还会详细阐述Encoder跟Decoder内部的架构。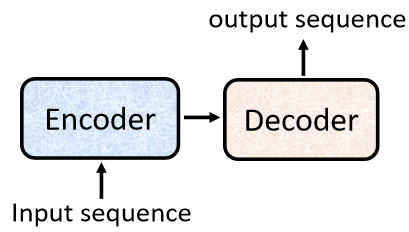
我们要学习的transformer就是一个典型Seq2seq的model。
Encoder
功能
Encoder要做的事情,就是给一排向量,输出另外一排向量。
给一排向量、输出一排向量这件事情,很多模型都可以做到,可能第一个想到的是,我们刚刚讲完的self-attention,其实不只self-attention,RNN CNN其实也都能够做到input一排向量,output另外一个同样长度的向量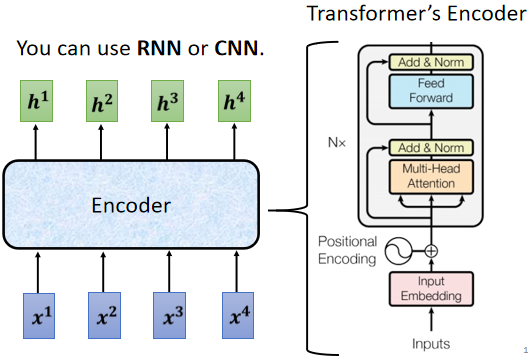
Transformer的Encoder,用的就是self-attention。
结构
现在的Encoder里面,会分成很多的block,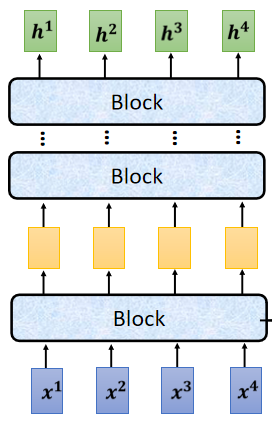
每一个block都是输入一排向量,输出一排向量,输入一排向量给第一个block,第一个block输出另外一排向量,再输给另外一个block,到最后一个block,会输出最终的vector sequence,但每一个block其实并不是neural network的一层,每一个block里面做的事情,是好几个layer在做的事情,在transformer的Encoder里面,每一个block做的事情大致如图所示,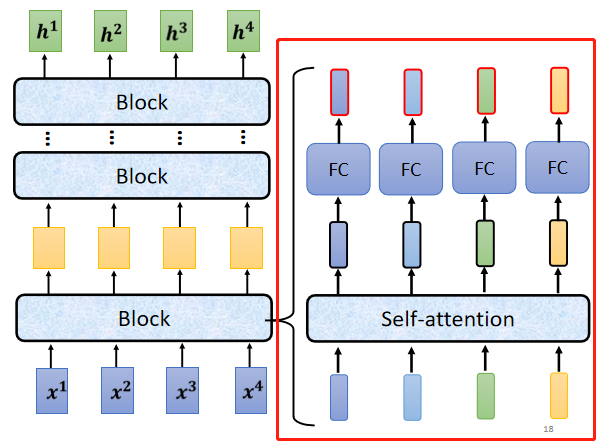
- 先做一个self-attention,input一排vector以后,做self-attention,考虑整个sequence的信息,Output另外一排vector。
- 接下来这一排vector,会再丢到fully connected的feed forward network里面,再output另外一排vector,这一排vector就是block的输出
事实上在原来的transformer里面,它做的事情是更复杂的
在之前self-attention的时候,我们说输入一排vector,就输出一排vector,这边的每一个vector,它是考虑了所有的input以后,所得到的结果,在transformer里面,它加入了一个设计,我们不只是输出这个vector,我们还要把这个vector加上它的input,它要把input拿来直接加给输出,得到新的output。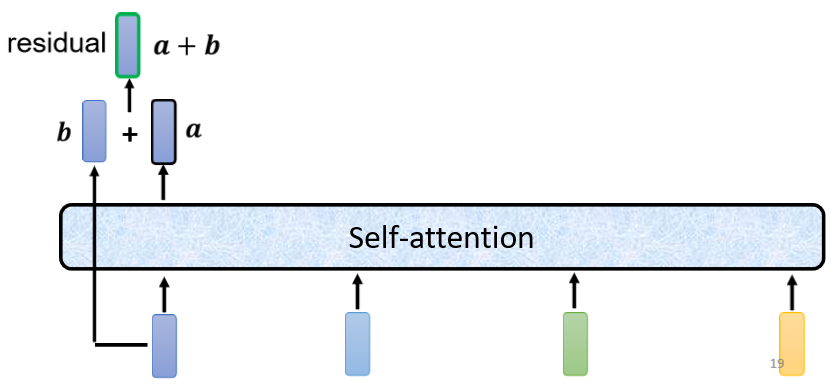
这样的network架构,叫做residual connection(残差连接),其实这种residual connection,在deep learning的领域用的是非常的广泛,关于residual connection的详细介绍,日后的笔记会有阐述,我们目前需要了解的是有一种network设计的架构,叫做residual connection,它会把input直接跟output加起来,得到新的vector
得到residual的结果以后,再做normalization,这边用的不是batch normalization,这边用的叫layer normalization,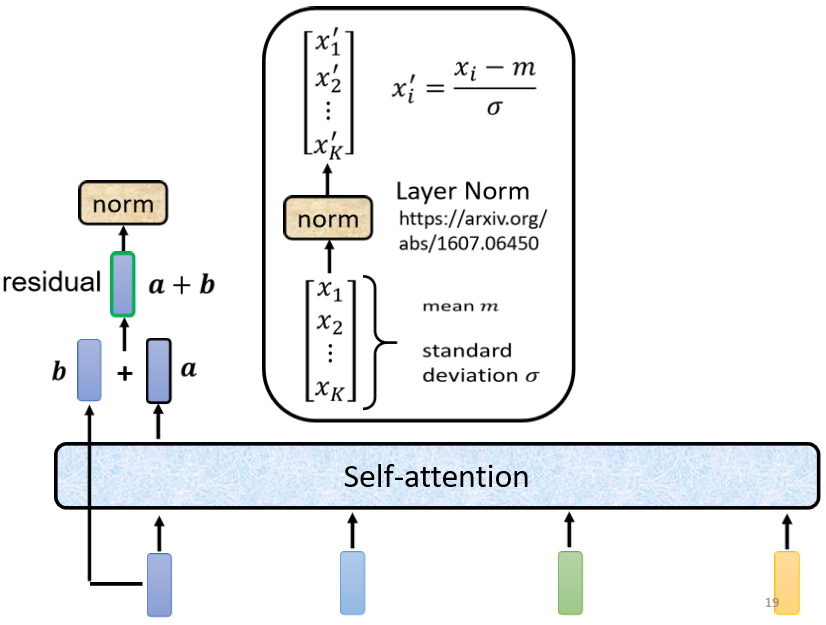
layer normalization做的事情,比bacth normalization更简单一点。
输入一个向量输出另外一个向量,不需要考虑batch,它会把输入的这个向量,计算它的mean跟standard deviation。
但是要注意batch normalization是对不同example,不同feature的同一个dimension,去计算mean跟standard deviation、
但layer normalization,它是对同一个feature,同一个example里面,不同的dimension,去计算mean跟standard deviation。
得到layer normalization的输出以后,它的这个输出才是FC network的输入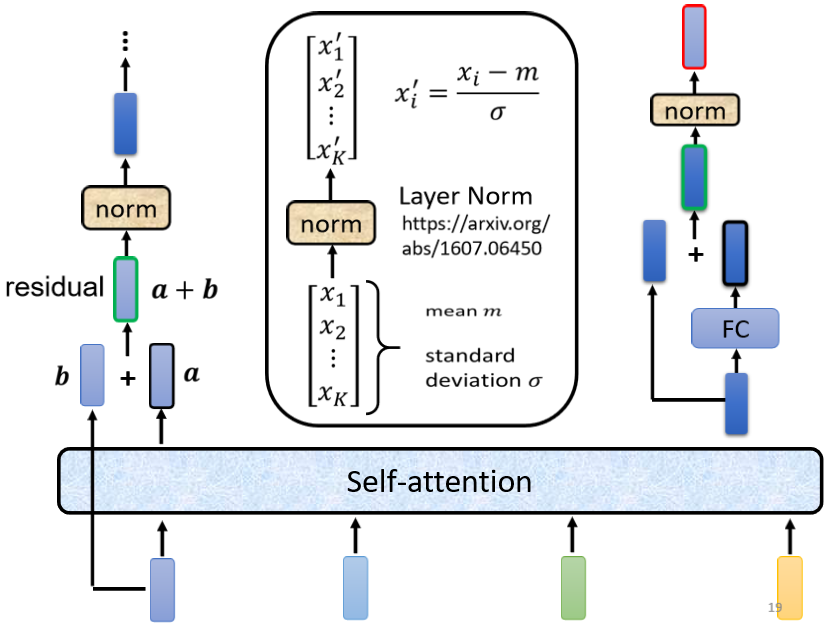
FC network这边也有residual的架构,所以我们会把FC network的input,跟它的output加起来做一下residual,得到新的输出,然后把residual的结果再做一次layer normalization,得到的输出,才是residual network里面一个block的输出,所以这个是挺复杂的。
总结
- 首先要有self-attention,并在input的地方加上positional encoding,如果你只用self-attention,你没有位置的信息,所以你需要加上positional的information,然后在这个图上特别强调positional的information。
- Multi-Head Attention,这个就是self-attention的block,这边特别强调它是Multi-Head的self-attention。
- Add&norm,就是residual加layer normalization,我们刚才说self-attention有加上residual的connection,加下来还要过layer normalization,图上的Add&norm,就是residual加layer norm的意思。
- 接下来,过完fc的feed forward network以后再做一次Add&norm才是一个block的输出,
然后这个block会重复n次,就是transformer的encoder。
这个encoder的network架构是按照原始的论文来设计,但原始论文的设计不代表它是最optimal的设计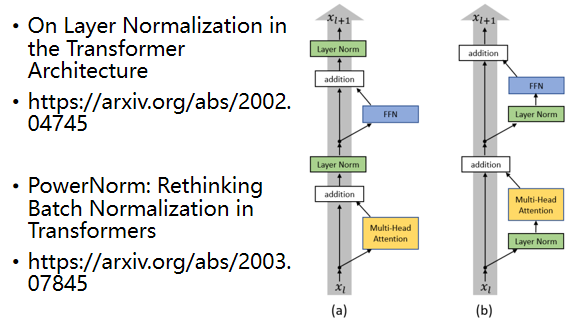
有一篇文章叫on layer normalization in the transformer architecture,它问的问题就是为什么我们是先做residual再做layer normalization,能不能做residual以后再做layer normalization,你可以看到左边这个图是原始的transformer,右边这个图是把block更换一下顺序以后的transformer,更换一下顺序以后结果是会比较好的,这代表原始的transformer的架构,并不是一个最optimal的设计,你永远可以思考有没有更好的设计方式。
Decoder
功能
Decoder其实有两种,我们主要介绍比较常见的Autoregressive Decoder。
Decoder 做的事情就是把 Encoder 的输出先读进去,最后产生最后的输出。
以语音识别为例,Decoder要产生一段文字,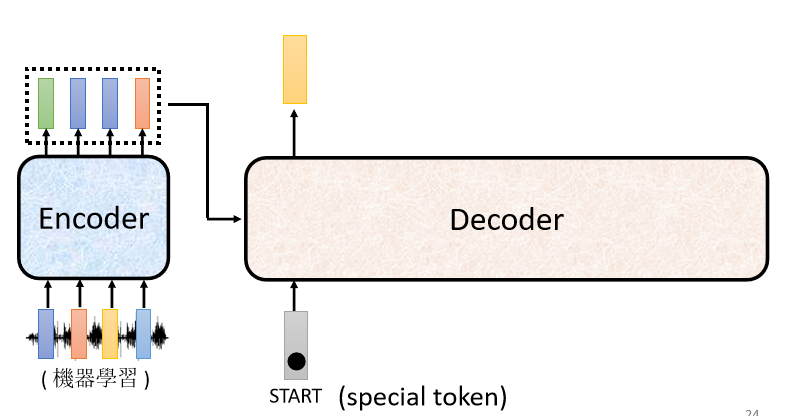
首先,你要先给它一个特殊的符号,这个特殊的符号代表开始,这个是一个Special的Token,你需要在本来Decoder可能产生的文字里面,多加一个特殊的字,这个字代表了BEGIN,代表了开始这个事情。
在机器学习里面,假设你要处理NLP的问题,每一个Token,可以把它用一个One-Hot的Vector来表示,BEGIN也是用One-Hot Vector来表示,其中一维是1,其他是0。
接下来Decoder会输出一个向量,这个Vector的长度跟你的Vocabulary Size是一样的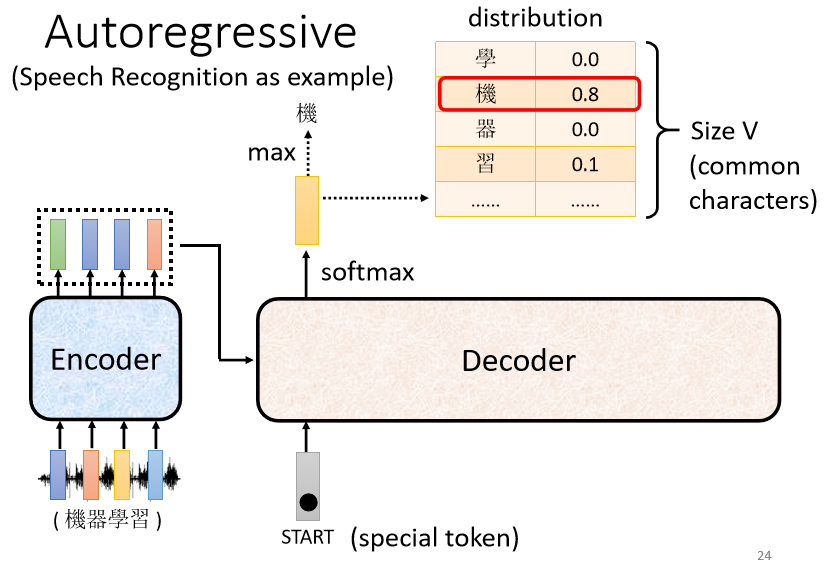
Vocabulary Size是什么意思呢?
假设我们今天做的是中文的语音识别,我们Decoder输出的是中文,Vocabulary Size,可能就是中文的方块字的数目,就是输出的最小单位的量。
不同的语言,它输出的单位取决于你对语言的理解,比如说英文,你可以选择输出字母的A到Z,但你可能会觉得字母这个单位太小了,有人可能会选择输出英文的词汇,英文的词汇是用空白作为间隔的,但如果都用词汇当作输出,又太多了,所以有一些方法,可以把英文的前缀字根切出来,拿前缀字根当作单位。
图中每一个中文的字都会对应到一个数值,因为在产生这个向量之前会先跑一个Softmax,就跟做分类一样,这一个向量里面的分数是一个Distribution(分布),也就是,它这个向量里面的值全部加起来总和会是1,分数最高的一个中文字,它就是最终的输出。
在这个例子里面,“机”的分数最高,所以“机”就是Decoder第一个输出,然后接下来把“机”当做是Decoder新的Input。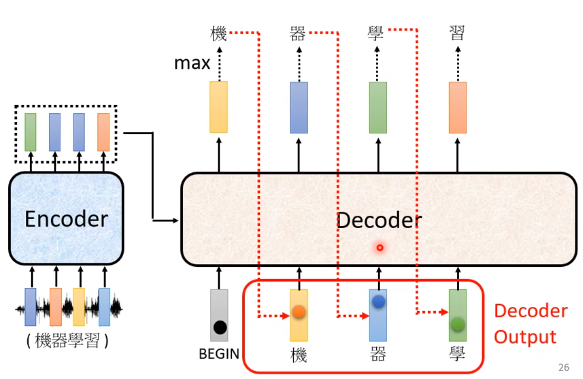
原来Decoder的Input,只有BEGIN这个特别的符号,现在它除了BEGIN以外,它还有“机”作为它的Input,所以Decoder现在它有两个输入,一个是BEGIN这个符号,一个是“机”,根据这两个输入,它输出一个蓝色的向量,根据这个蓝色的向量里面,给每一个中文的字的分数,我们会决定第二个输出,哪一个字的分数最高,它就是输出,假设“器”的分数最高,“器”就是输出,依此类推。
Encoder这边也有给decoder的输入,等一下再说对于Encoder的输入Decoder是怎么处理的。
这边有一个关键的地方,我们特别用红色的虚线把它标出来,也就是说Decoder看到的输入,有它在前一个时间点自己的输出,Decoder会把自己的输出,当做接下来的输入一部分。
如果Decoder看到错误的输入会不会造成Error Propagation(误差传播)的问题呢?
Error Propagation就是,一步错步步错,比如不小心把机器的“器”,不小心写成天气的“气”,会不会接下来就整个句子都没有办法再产生正确的词汇了?
有可能,我们最后会提到这个问题要怎么处理,我们暂时先无视这个问题。
结构
我们先来看一下这个Decoder内部的结构,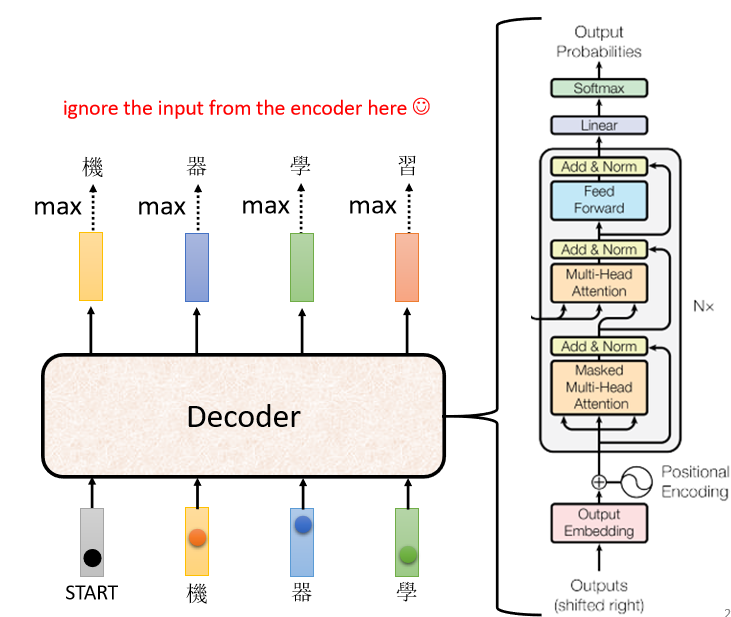
我们把Encoder跟Decoder放在一起,你会发现如果我们把Decoder中间这一块把它遮住,其实Encoder跟Decoder,并没有那么大的差别。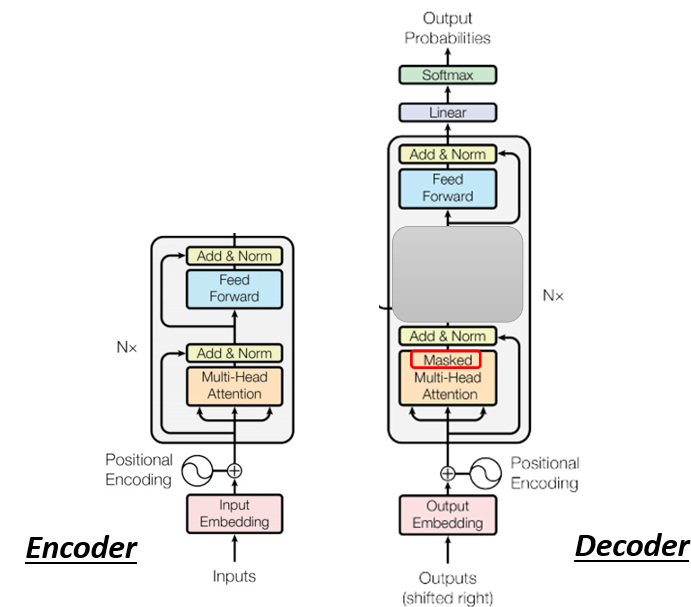
当我们把中间这一块遮起来以后,我们之后再讲遮起来这一块里面做了什么事,Encoder这边Multi-Head Attention,然后Add&Norm,Feed Forward,Add&Norm,重复N次,Decoder其实也是一样,只是最后,我们会再做一个Softmax,使得它的输出变成一个概率。
这边有一个不一样的地方是,在Decoder这边,Multi-Head Attention这一个Block上面,还加了一个Masked。
我们原来的Self-Attention,Input一排Vector,Output另外一排Vector,这一排Vector每一个输出,都要看过完整的Input以后,才做决定,所以输出$b^1$的时候,其实是根据$b^1$到$b^4$所有的信息去输出$b^1$。
Masked Attention的不同点是,现在我们不能再看右边的部分,也就是产生$b^1$的时候,我们只能考虑$a^1$的信息,不能够再考虑$a^2a^3a^4$;产生$b^2$的时候,我们只能考虑$a^1a^2$的信息,不能够再考虑$a^3a^4$;产生$b^3$的时候,我们只能考虑$a^1a^2a^3$的信息,不能够再考虑$a^4$;产生$b^4$的时候,我们可以考虑所有的信息。
细化到操作如下,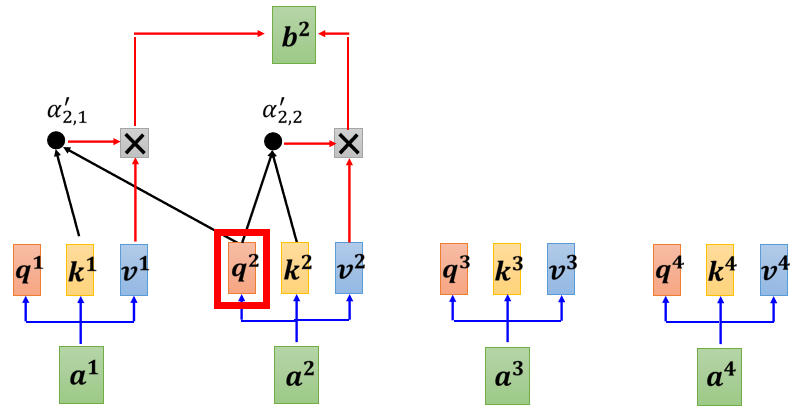
为什么需要加Masked?
对Decoder而言,先有$a^1$才有$a^2$,才有$a^3$$a^4$,所以实际上,当你有$a^2$,要计算$b^2$的时候,你是没有$a^3$和$a^4$的,所以就没有办法把$a^3$$a^4$ 考虑进来。
还有一个非常关键的问题,Decoder必须自己决定,输出的Sequence的长度。
可是到底输出的Sequence的长度应该是多少,我们不知道,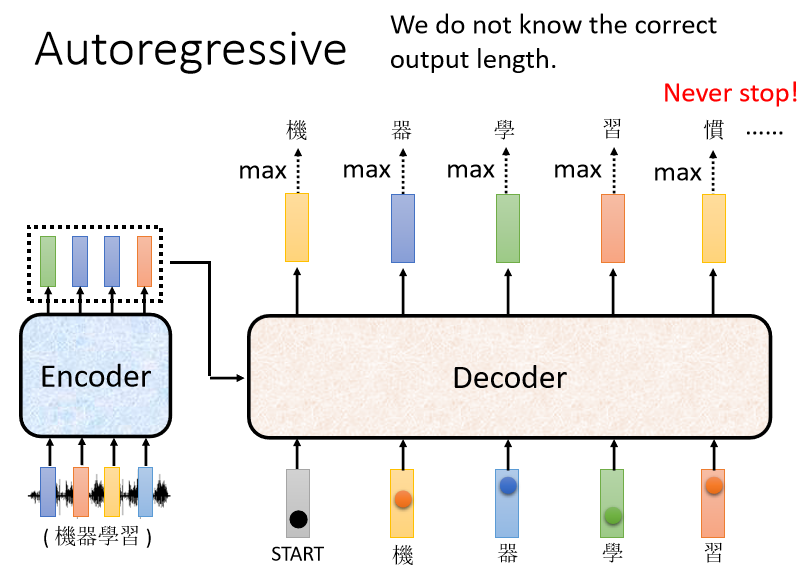
所以我们要让Decoder自己可以输出一个结束,所要准备一个特别的符号叫做“断”,用END来表示这个特殊的符号。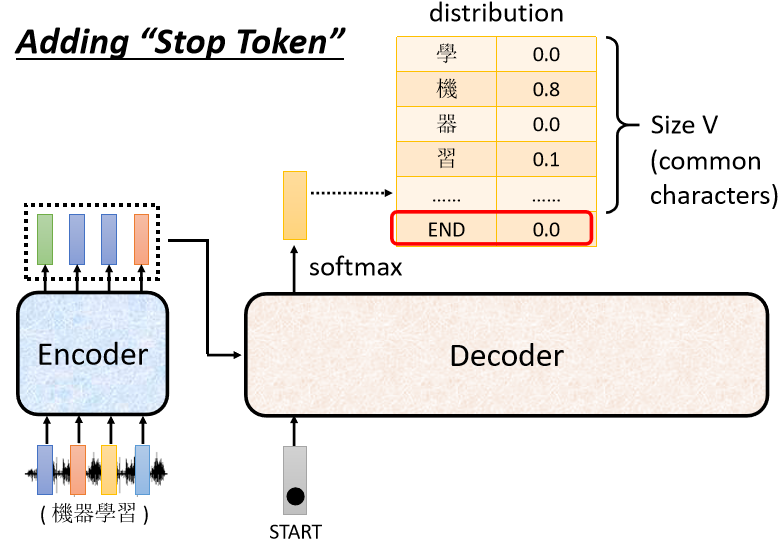
我们现在把“习”当作输入以后,此时Decoder看到了Encoder输出的这个Embedding,看到了“BEGIN”,看到了“机”“器”“学”“习”以后,看到这些信息以后它要知道语音识别的结果已经结束了,不需要再产生更多的词汇了。
此时向量END,就是断的那个符号,它的概率必须要是最大的,然后你就输出断这个符号,之后整个Decoder产生Sequence的过程,就结束了。
这个就是Autoregressive Decoder的机制。
Decoder–Non-autoregressive(NAT)
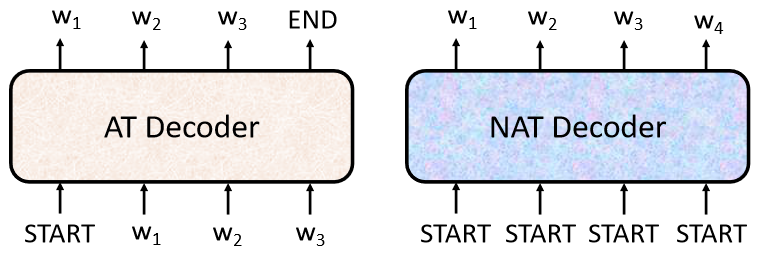
NAT的Decoder输入的是一整排的BEGIN的Token,把一排BEGIN的Token都丢给它,让它一次产生一排Token就结束了。
举例来说,如果你丢给它4个BEGIN的Token,它就产生4个中文的字,变成一个句子结束,所以它只要一个步骤,就可以完成句子的生成。
这边有一个问题:刚才不是说不知道输出的长度应该是多少吗,那我们这边怎么知道BEGIN要放多少个,当做NAT Decoder的收入?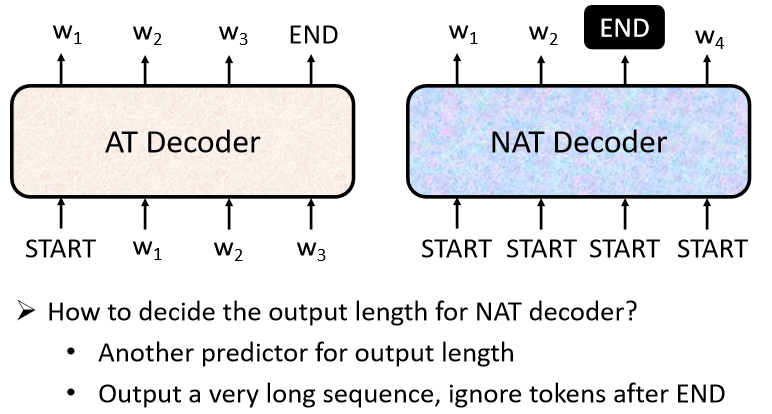
这件事没有办法很直接的知道,所以有两个做法:
- 一个做法是,你另外learn一个Classifier,这个Classifier,它输入Encoder的Input,然后输出是一个数字,这个数字代表Decoder应该要输出的长度,这是一种可能的做法。
- 另一种可能做法就是,你就假设一个句子长度的上限,然后B给它一堆BEGIN的Token,假设现在输出的句子的长度绝对不会超过300个字,你就给它300个BEGIN,然后就会输出300个字,然后看看什么地方输出END,END右边的就当做它没有输出,就结束了。
NAT的Decoder有什么样的好处呢?
- 并行化,AT的Decoder在输出它的句子的时候,是逐字产生的,假设要输出长度一百个字的句子,那你就需要做一百次的Decode但是NAT的Decoder不是这样,不管句子的长度如何,都是一个步骤就产生出完整的句子,所以在速度上NAT的Decoder会跑得比AT的Decoder要快,NAT Decoder的想法是有这个Transformer以后,有这种Self-Attention的Decoder以后才有的,因为以前如果你是用LSTM,RNN的话,你就算给它一排BEGIN也没有办法同时产生全部的输出,它的输出还是一个一个产生的,所以在没有这个Self-Attention之前,不会有人想要做什么NAT的Decoder,不过自从有了Self-Attention以后,那NAT的Decoder,现在就算是一个热门的研究的主题了。
- NAT的Decoder有一个好处就是可以控制输出的长度,你比如有一个Classifier决定NAT的Decoder应该输出的长度,那如果在做语音合成的时候,假设你现在突然想要让你的系统讲快一点,就把那个Classifier的Output除以二,它讲话速度就变两倍快,如果你想要这个讲话放慢速度,那你就把那个Classifier输出的那个长度,它Predict出来的长度乘两倍,那你的这个Decoder,说话的速度就变两倍慢。
NAT的Decoder,它的Performance,往往都不如AT的Decoder,要让NAT的Decoder,跟AT的Decoder Performance一样好,你必须要用非常多的Trick才能够办到,AT的Decoder随便Train一下,NAT的Decoder你要花很多力气,才有可能跟AT的Performance差不多。
Encoder-Decoder
接下来要讲Encoder跟Decoder它们中间是怎么传递信息的了,也就是刚才我们刻意把它遮起来的那一块。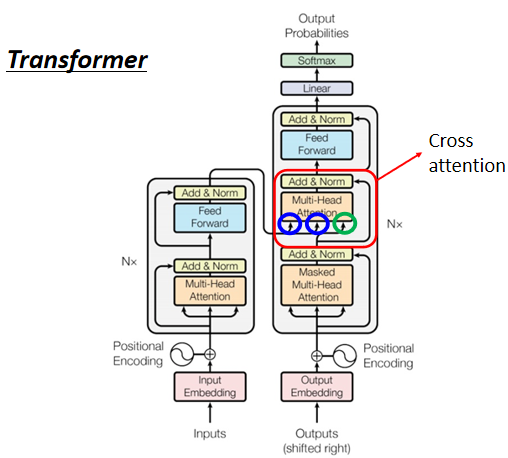
这块叫做Cross Attention,它是连接Encoder跟Decoder之间的桥梁,Encoder提供两个箭头,然后Decoder提供了一个箭头,所以从左边这两个箭头,Decoder可以读到Encoder的输出。
运作的过程如下,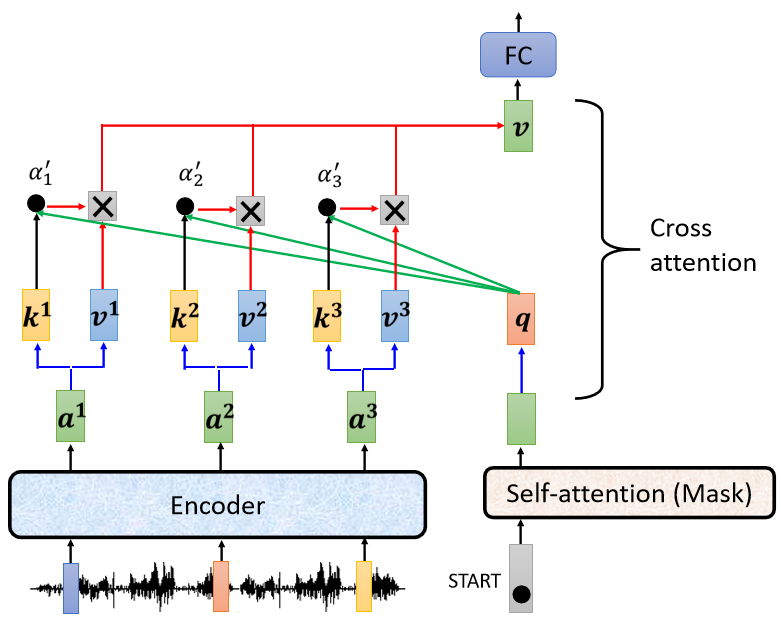
- Encoder输入一排向量,接着输出一排向量$a^1a^2a^3$。
- 接下来Decoder会先读BEGIN这个Special的Token,BEGIN这个Special的Token读进来以后会经过Mask Self-Attention得到一个向量。
- 接下来把这个向量乘上一个矩阵做一个Transform,得到一个Query叫做q。
- encoder输出的$a^1a^2a^3$会产生$k^1k^2k^3$和$v^1v^2v^3$。
- q和$k^1k^2k^3$计算Attention的分数,得到$\alpha^1\alpha^2\alpha^3$,做一下Normalization,这边加一个’,代表它做过Normalization。
- 把$\alpha^1\alpha^2\alpha^3$分别乘上$v^1v^2v^3$,再把它Weighted Sum加起来会得到v。
V接下来会输入到Fully-Connected Network做接下来的处理,而以上的五步就叫做Cross Attention。
Decoder就是通过产生q去Encoder这边综合信息产生V,当做接下来的Fully-Connected Network的Input。
假设第一个字产生一个“机”,现在产生第二个字,接下来的运作也是一模一样的,输入BEGIN和“机”产生一个向量,这个向量一样乘上一个Linear的Transform……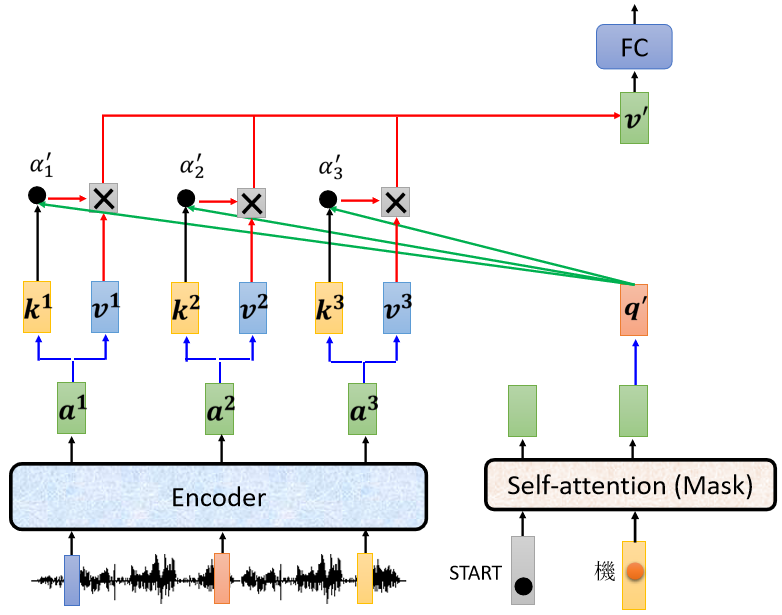
Training tips
以语音识别为例,说明一个transformer模型的训练技巧。
首先要有训练资料,要收集一大堆的声音讯号,每一句声音讯号都要有人来辨识它的对应的词汇是什么。
比如我们已经知道说输入这段声音讯号,第一个应该要输出的中文字是“机”,所以当我们把BEGIN,丢给这个model的时候,它第一个输出应该要跟“机”越接近越好,“机”这个字会被表示成一个One-Hot的Vector,在这个Vector里面,只有“机”对应的维度是1,其他都是0,这是正确答案,Decoder的输出是一个Distribution,是一个概率的分布,我们会希望这一个概率的分布,跟这个One-Hot的Vector越接近越好,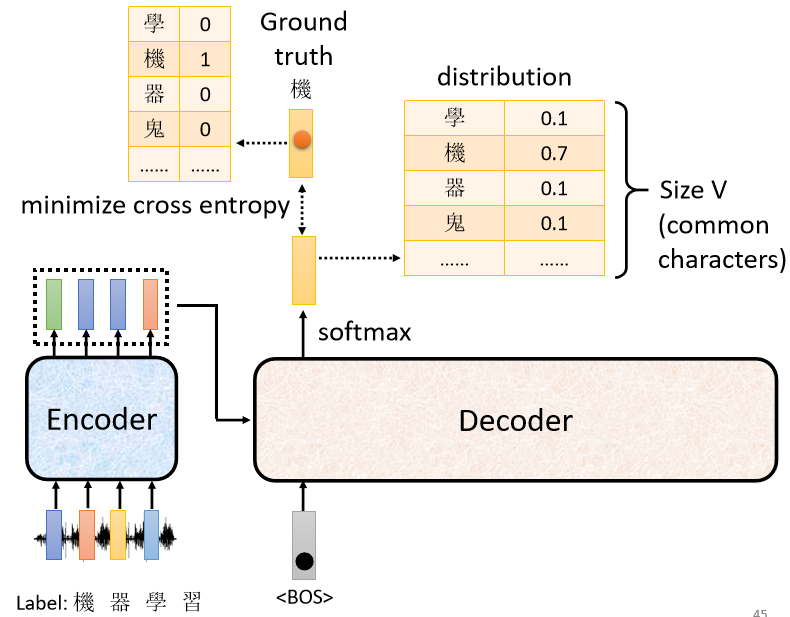
所以我们会去计算Ground Truth跟Distribution之间的Cross Entropy,我们希望Cross Entropy的值越小越好。
实际上训练的时候,我们已经知道输出应该是“机器学习”这四个字,就告诉你的Decoder,现在你第一次的输出第二次的输出,第三次的输出第四次输出,应该分别就是“机”“器”“学”跟“习”,这四个中文字的One-Hot Vector,我们希望我们的输出跟这四个字的One-Hot Vector越接近越好。
在训练的时候,每一个输出都会有一个Cross Entropy,每一个输出跟它对应的正确答案都有一个Cross Entropy,我们要希望所有的Cross Entropy的总和最小,越小越好。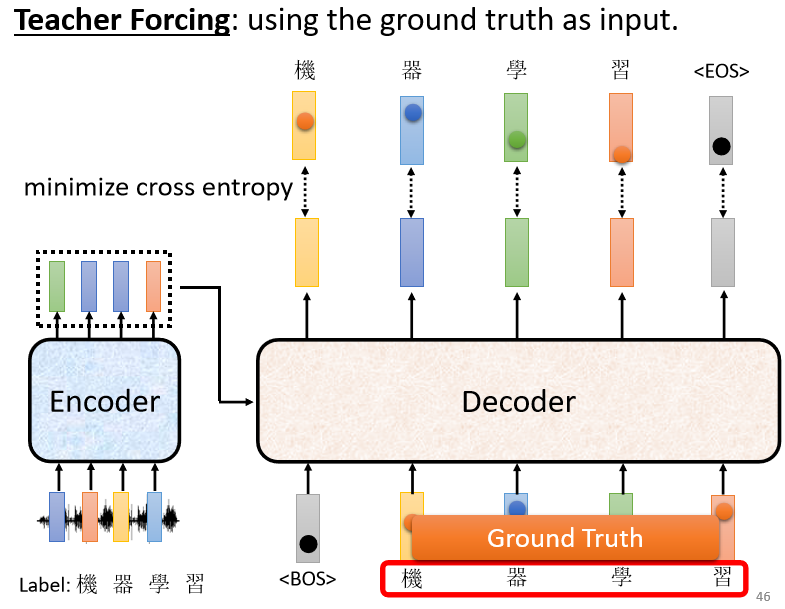
Decoder的训练:把Ground Truth,正确答案给它,希望Decoder的输出跟正确答案越接近越好。
这边有一件值得我们注意的事情,在训练的时候我们会给Decoder看正确答案,也就是我们会告诉它:
- 在已经有“BEGIN”,在有“机”的情况下你就要输出“器”
- 有“BEGIN”有“机”有“器”的情况下输出“学”
- 有“BEGIN”有“机”有“器”有“学”的情况下输出“习”
- 有“BEGIN”有“机”有“器”有“学”有“习”的情况下,你就要输出“断”
我们会在输入的时候给它正确的答案,这件事情叫做Teacher Forcing
Scheduled Sampling
这个时候会有一个问题:
训练的时候,Decoder有看到正确答案,但是测试的时候没有正确答案可以给Decoder看
在真正使用这个模型Inference的时候,Decoder看到的是自己的输入,这中间显然有一个Mismatch,这个不一致的现象叫做Exposure Bias(曝光偏差),如何解决这个问题呢?
有一个可思考的方向是,给Decoder的输入加一些错误的东西,不要给Decoder都是正确的答案,偶尔给它一些错的东西,它反而会学得更好,这一招叫做Scheduled Sampling,但是Scheduled Sampling会伤害到Transformer平行化的能力,具体的细节可以看以下的论文
Copy Mechanism
Decoder没有必要自己创造输出出来,它需要做的事情,也许是从输入的东西里面复制一些东西,比如做聊天机器人。
对机器来说,它没有必要创造库洛洛这个词汇,这对机器来说一定会是一个非常怪异的词汇,它在训练资料里面可能一次也没有出现过,所以它不太可能正确地产生这段词汇出来。
但是假设今天机器它在学的时候,它学到的是看到输入的时候说我是某某某,就直接把某某某复制出来说某某某你好。
这样的机器的训练显然会比较容易,它比较有可能得到正确的结果,所以复制对于对话来说是一个非常需要的能力。
Guided Attention
Guiding Attention要做的事情就是,要求机器在做Attention的时候,是有固定的方式的,举例来说,对语音合成或者是语音识别来说,我们认为Attention应该就是由左向右。
在这个例子里面,我们用红色的这个曲线,来代表Attention的分数,越高就代表Attention的值越大。
我们以语音合成为例,输入是一串文字,在合成声音的时候,显然是由左念到右,所以机器应该是,先看最左边输入的词汇产生声音,再看中间的词汇产生声音,再看右边的词汇产生声音。
如果在做语音合成的时候,机器的Attention是颠三倒四的,它先看最后面,接下来再看前面,那再胡乱看整个句子,那显然有些是做错了。
所以Guiding Attention要做的事情就是,强迫Attention有一个固定的样貌,那如果你对这个问题本身就已经有正确的理解,比如知道语音合成TTS,Attention的分数,Attention的位置都应该由左向右,那就直接把这个限制,放进你的Training里面,要求机器学到Attention,就应该要由左向右。
如果想要深入了解Guiding Attention,大家可以自行Google,比如说Mnotonic Attention,或Location-Aware Attention等关键词。
Beam Search
举一个例子,假设我们现在的这个Decoder就只能产生两个字,一个叫做A一个叫做B,对Decoder而言,它做的事情就是,每一次在A B里面决定一个,比如决定了A以后,再把A当做输入,然后再决定A B要选哪一个。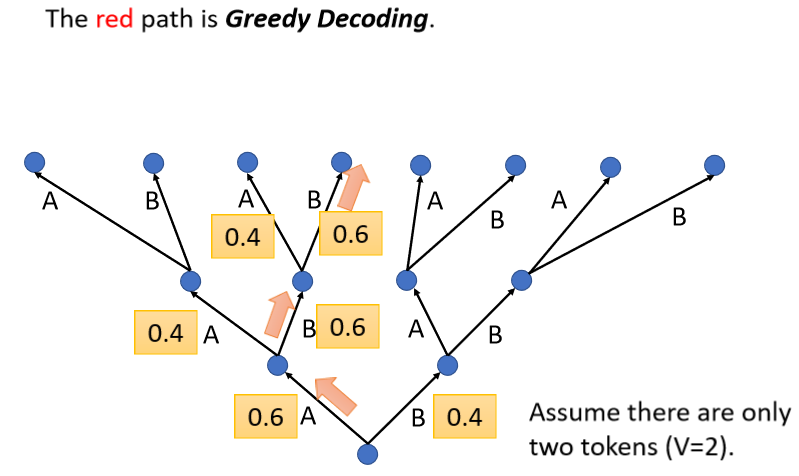
我们刚才讲的Process里面,每一次Decoder都是选分数最高的那一个,我们每次都是选Max的那一个,所以假设A的分数0.6,B的分数0.4,Decoder的第一次就会输出A,然后接下来假设B的分数0.6,A的分数0.4,Decoder就会输出B,像这样每次找分数最高的那个Token,每次找分数最高的那个字,来当做输出这件事情叫做Greedy Decoding。
Greedy Decoding一定是最好的方法吗,有没有可能我们在某一步的时候,选分低的反而会更好,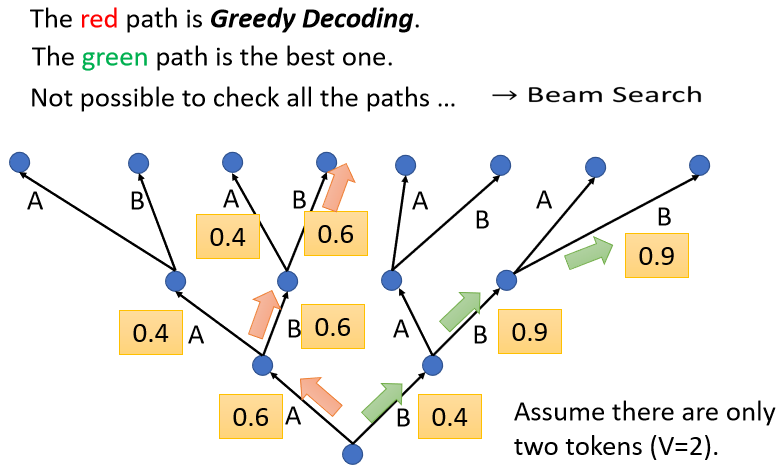
比如说第一步虽然B是0.4,但我们就先选0.4这个B,然后接下来我们选了B以后,也许接下来的B的可能性就大增,就变成0.9,然后接下来第三个步骤,B的可能性也是0.9。
如果你比较红色的这一条路跟绿色这条路的话,你会发现说绿色这一条路,虽然一开始第一个步骤,你选了一个比较差的输出,但是接下来的结果是好的。
所以我们要怎么找到,这个最好的绿色这一条路呢,也许一个可能是爆搜所有可能的路径,但问题是我们并没有办法爆搜所有可能的路径,如果是在输出中文,日常使用的中文有至少4000个字,所以这个树每一个地方分叉,都是至少4000个可能的路径,你走两三步以后,你就无法穷举。
而有一个算法叫做Beam Search(束搜索),它用比较有效的方法找一个不是完全精准的的路,这个技术叫做Beam Search,有兴趣的可以自行搜索。
本文尚待回答的问题(后续文章更新)
- Resnet的相关知识
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!