深度学习-9-pytorch-2-数据处理
本文最后更新于:2021年8月11日 下午
创作声明:主要内容参考于张贤同学https://zhuanlan.zhihu.com/p/265394674
数据模块又可以细分为 4 个部分:
- 数据收集:样本和标签。
- 数据划分:训练集、验证集和测试集
- 数据读取:对应于 PyTorch 的 DataLoader。其中 DataLoader 包括 Sampler 和 DataSet。Sampler 的功能是生成索引, DataSet 是根据生成的索引读取样本以及标签。
- 数据预处理:对应于 PyTorch 的 transforms
DataLoader 与 DataSet(数据读取)
torch.utils.data.DataLoader()
1 | |
功能:构建可迭代的数据装载器
- dataset: Dataset 类,决定数据从哪里读取以及如何读取
- batchsize: 批大小
- num_works:num_works: 是否多进程读取数据
- sheuffle: 每个 epoch 是否乱序
- drop_last: 当样本数不能被 batchsize 整除时,是否舍弃最后一批数据
Epoch, Iteration, Batchsize
- Epoch: 所有训练样本都已经输入到模型中,称为一个 Epoch
- Iteration: 一批样本输入到模型中,称为一个 Iteration
- Batchsize: 批大小,决定一个 iteration 有多少样本,也决定了一个 Epoch 有多少个 Iteration
假设样本总数有 80,设置 Batchsize 为 8,则共有 $80 \div 8=10$ 个 Iteration。这里 $1 Epoch = 10 Iteration$。
假设样本总数有 86,设置 Batchsize 为 8。如果drop_last=True则共有 10 个 Iteration;如果drop_last=False则共有 11 个 Iteration。
torch.utils.data.Dataset
功能:Dataset 是抽象类,所有自定义的 Dataset 都需要继承该类,并且重写__getitem()__方法和__len__()方法 。__getitem()__方法的作用是接收一个索引,返回索引对应的样本和标签,这是我们自己需要实现的逻辑。__len__()方法是返回所有样本的数量。
数据读取包含 3 个方面
- 读取哪些数据:每个 Iteration 读取一个 Batchsize 大小的数据,每个 Iteration 应该读取哪些数据。
- 从哪里读取数据:如何找到硬盘中的数据,应该在哪里设置文件路径参数。
- 如何读取数据:不同的文件需要使用不同的读取方法和库。
这里的路径结构如下,有两类人民币图片:1 元和 100 元,每一类各有 100 张图片。
- RMB_data
- 1
- 100
首先划分数据集为训练集、验证集和测试集,比例为 8:1:1。
数据划分好后的路径构造如下:
- rmb_split
- train
- 1
- 100
- valid
- 1
- 100
- test
- 1
- 100
实现读取数据的 Dataset,编写一个get_img_info()方法,读取每一个图片的路径和对应的标签,组成一个元组,再把所有的元组作为 list 存放到self.data_info变量中,这里需要注意的是标签需要映射到 0 开始的整数:rmb_label = {"1": 0, "100": 1}。然后在Dataset 的初始化函数中调用get_img_info()方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22@staticmethod
def get_img_info(data_dir):
data_info = list()
# data_dir 是训练集、验证集或者测试集的路径
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
# dirs ['1', '100']
for sub_dir in dirs:
# 文件列表
img_names = os.listdir(os.path.join(root, sub_dir))
# 取出 jpg 结尾的文件
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
# 图片的绝对路径
path_img = os.path.join(root, sub_dir, img_name)
# 标签,这里需要映射为 0、1 两个类别
label = rmb_label[sub_dir]
# 保存在 data_info 变量中
data_info.append((path_img, int(label)))
return data_info然后在1
2
3
4
5
6
7
8
9def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
# data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.data_info = self.get_img_info(data_dir)
self.transform = transform__getitem__()方法中根据index 读取self.data_info中路径对应的数据,并在这里做 transform 操作,返回的是样本和标签。在1
2
3
4
5
6
7
8
9def __getitem__(self, index):
# 通过 index 读取样本
path_img, label = self.data_info[index]
# 注意这里需要 convert('RGB')
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
# 返回是样本和标签
return img, label__len__()方法中返回self.data_info的长度,即为所有样本的数量。1
2
3# 返回所有样本的数量
def __len__(self):
return len(self.data_info)
- train
简单的训练示范
在train_lenet.py中,分 5 步构建模型。
第 1 步设置数据。首先定义训练集、验证集、测试集的路径,定义训练集和测试集的transforms。然后构建训练集和验证集的RMBDataset对象,把对应的路径和transforms传进去。再构建DataLoder,设置 batch_size,其中训练集设置shuffle=True,表示每个 Epoch 都打乱样本。
1 | |
第 2 步构建模型,这里采用经典的 Lenet 图片分类网络。
1 | |
第 3 步设置损失函数,这里使用交叉熵损失函数。
1 | |
第 4 步设置优化器。这里采用 SGD 优化器。
1 | |
第 5 步迭代训练模型,在每一个 epoch 里面,需要遍历 train_loader 取出数据,每次取得数据是一个 batchsize 大小。这里又分为 4 步。第 1 步进行前向传播,第 2 步进行反向传播求导,第 3 步使用optimizer更新权重,第 4 步统计训练情况。每一个 epoch 完成时都需要使用scheduler更新学习率,和计算验证集的准确率、loss。
1 | |
我们可以看到每个 iteration,我们是从train_loader中取出数据的。
1 | |
这里我们没有设置多进程,会执行_SingleProcessDataLoaderIter的方法。我们以_SingleProcessDataLoaderIter为例。在_SingleProcessDataLoaderIter里只有一个方法_next_data(),如下:
1 | |
在该方法中,self._next_index()是获取一个 batchsize 大小的 index 列表,代码如下:
1 | |
其中调用的sampler类的__iter__()方法返回 batch_size 大小的随机 index 列表。
1 | |
然后再返回看 dataloader的_next_data()方法:
1 | |
在第二行中调用了self._dataset_fetcher.fetch(index)获取数据。这里会调用_MapDatasetFetcher中的fetch()函数:
1 | |
这里调用了self.dataset[idx],这个函数会调用dataset.getitem()方法获取具体的数据,所以__getitem__()方法是我们必须实现的。我们拿到的data是一个 list,每个元素是一个 tunple,每个 tunple 包括样本和标签。所以最后要使用self.collate_fn(data)把 data 转换为两个 list,第一个 元素 是样本的batch 形式,形状为 [16, 3, 32, 32] (16 是 batch size,[3, 32, 32] 是图片像素);第二个元素是标签的 batch 形式,形状为 [16]。
所以在代码中,我们使用inputs, labels = data来接收数据。
PyTorch 数据读取流程图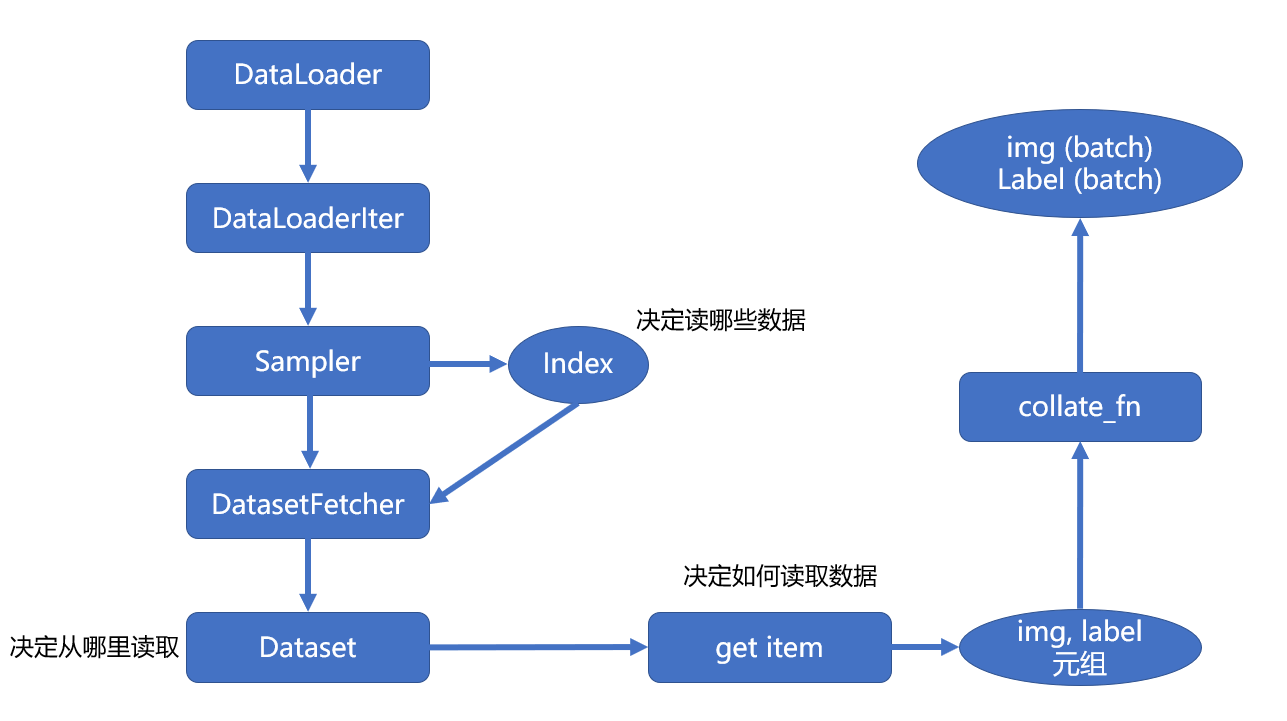
首先在 for 循环中遍历DataLoader,然后根据是否采用多进程,决定使用单进程或者多进程的DataLoaderIter。
在DataLoaderIter里调用Sampler生成Index的 list,再调用DatasetFetcher根据index获取数据。
在DatasetFetcher里会调用Dataset的__getitem__()方法获取真正的数据。这里获取的数据是一个 list,其中每个元素是 (img, label) 的元组。
再使用 collate_fn()函数整理成一个 list,里面包含两个元素,分别是 img 和 label 的tenser。
PyTorch 的数据增强(数据预处理)
我们在安装PyTorch时,还安装了torchvision,这是一个计算机视觉工具包。有 3 个主要的模块:
- torchvision.transforms: 里面包括常用的图像预处理方法
- torchvision.datasets: 里面包括常用数据集如 mnist、CIFAR-10、Image-Net 等
- torchvision.models: 里面包括常用的预训练好的模型,如 AlexNet、VGG、ResNet、GoogleNet 等
深度学习模型是由数据驱动的,数据的数量和分布对模型训练的结果起到决定性作用。所以我们需要对数据进行预处理和数据增强。下面是用数据增强,从一张图片经过各种变换生成 64 张图片,增加了数据的多样性,这可以提高模型的泛化能力。
常用的图像预处理方法有:
- 数据中心化
- 数据标准化
- 缩放
- 裁剪
- 旋转
- 翻转
- 填充
- 噪声添加
- 灰度变换
- 线性变换
- 仿射变换
- 亮度、饱和度以及对比度变换。
在人民币图片二分类实验中,我们对数据进行了一定的增强。
1 | |
当我们需要多个transforms操作时,需要作为一个list放在transforms.Compose中。需要注意的是transforms.ToTensor()是把图片转换为张量,同时进行归一化操作,把每个通道 0255 的值归一化为 01。在验证集的数据增强中,不再需要transforms.RandomCrop()操作。然后把这两个transform操作作为参数传给Dataset,在Dataset的__getitem__()方法中做图像增强。
1 | |
其中self.transform(img)会调用Compose的__call__()函数:
1 | |
可以看到,这里是遍历transforms中的函数,按顺序应用到 img 中。
transforms.Normalize
1 | |
功能:逐 channel 地对图像进行标准化
output = ( input - mean ) / std
- mean: 各通道的均值
- std: 各通道的标准差
- inplace: 是否原地操作
该方法调用的是F.normalize(tensor, self.mean, self.std, self.inplace)
而F.normalize()方法如下:首先判断是否为 tensor,如果不是 tensor 则抛出异常。然后根据inplace是否为 true 进行 clone,接着把mean 和 std 都转换为tensor (原本是 list),最后减去均值除以方差:tensor.sub_(mean[:, None, None]).div_(std[:, None, None])1
2
3
4
5
6
7
8
9
10
11
12def normalize(tensor, mean, std, inplace=False):
if not _is_tensor_image(tensor):
raise TypeError('tensor is not a torch image.')
if not inplace:
tensor = tensor.clone()
dtype = tensor.dtype
mean = torch.as_tensor(mean, dtype=dtype, device=tensor.device)
std = torch.as_tensor(std, dtype=dtype, device=tensor.device)
tensor.sub_(mean[:, None, None]).div_(std[:, None, None])
return tensor
对数据进行均值为 0,标准差为 1 的标准化,可以加快模型的收敛。
在逻辑回归的实验中,我们的数据生成代码如下:
1 | |
二十二种 transforms 图片数据预处理方法
这篇主要分为几个部分介绍 transforms:
- 裁剪
- 旋转和翻转
- 图像变换
- transforms 方法操作
- 自定义 transforms 方法
由于图片经过 transform 操作之后是 tensor,像素值在 0~1 之间,并且标准差和方差不是正常图片的。所以定义了transform_invert()方法。功能是对 tensor 进行反标准化操作,并且把 tensor 转换为 image,方便可视化。
我们主要修改的是transforms.Compose代码块中的内容,其中transforms.Resize((224, 224))是把图片缩放到 (224, 224) 大小 (下面的所有操作都是基于缩放之后的图片进行的),然后再进行其他 transform 操作。
原图如下:
经过缩放之后,图片如下:
裁剪
transforms.CenterCrop
1 | |
功能:从图像中心裁剪图片
- size: 所需裁剪的图片尺寸
transforms.CenterCrop(196)的效果如下:
如果裁剪的 size 比原图大,那么会填充值为 0 的像素。transforms.CenterCrop(512)的效果如下:
transforms.RandomCrop
1 | |
功能:从图片中随机裁剪出尺寸为 size 的图片,如果有 padding,那么先进行 padding,再随机裁剪 size 大小的图片。
size
padding: 设置填充大小
- 当为 a 时,上下左右均填充 a 个像素
- 当为 (a, b) 时,左右填充 a 个像素,上下填充 b 个像素
- 当为 (a, b, c, d) 时,左上右下分别填充 a,b,c,d
pad_if_need: 当图片小于设置的 size,是否填充
padding_mode:
- constant: 像素值由 fill 设定
- edge: 像素值由图像边缘像素设定
- reflect: 镜像填充,最后一个像素不镜像。([1,2,3,4] -> [3,2,1,2,3,4,3,2])
- symmetric: 镜像填充,最后一个像素也镜像。([1,2,3,4] -> [2,1,1,2,3,4,4,4,3])
fill: 当 padding_mode 为 constant 时,设置填充的像素值
transforms.RandomCrop(224, padding=16)的效果如下,这里的 padding 为 16,所以会先在 4 边进行 16 的padding,默认填充 0,然后随机裁剪出 (224,224) 大小的图片,这里裁剪了左上角的区域。transforms.RandomResizedCrop
1
torchvision.transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=2)功能:随机大小、随机宽高比裁剪图片。首先根据 scale 的比例裁剪原图,然后根据 ratio 的长宽比再裁剪,最后使用插值法把图片变换为 size 大小。
size: 裁剪的图片尺寸
scale: 随机缩放面积比例,默认随机选取 (0.08, 1) 之间的一个数
ratio: 随机长宽比,默认随机选取 ($\displaystyle\frac{3}{4}$, $\displaystyle\frac{4}{3}$ ) 之间的一个数。因为超过这个比例会有明显的失真
interpolation: 当裁剪出来的图片小于 size 时,就要使用插值方法 resize
size: 最后裁剪的图片尺寸
vertical_flip: 是否垂直翻转
由于这两个方法返回的是 tuple,每个元素表示一个图片,我们还需要把这个 tuple 转换为一张图片的tensor。代码如下:1
2transforms.FiveCrop(112),
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops]))并且把transforms.Compose中最后两行注释:
1
2# transforms.ToTensor(), # ToTensor()接收的参数是 Image,由于上面已经进行了 ToTensor(), 因此这里注释
# transforms.Normalize(norm_mean, norm_std), # 由于是 4 维的 Tensor,因此不能执行 Normalize() 方法transforms.ToTensor()接收的参数是 Image,由于上面已经进行了 ToTensor()。因此注释这一行。
transforms.Normalize()方法接收的是 3 维的 tensor (在 _is_tensor_image()方法 里检查是否满足这一条件,不满足则报错),而经过transforms.FiveCrop返回的是 4 维张量,因此注释这一行。
最后的 tensor 形状是 [ncrops, c, h, w],图片可视化的代码也需要做修改:
1 | |
旋转和翻转
transforms.RandomHorizontalFlip(RandomVerticalFlip)
1 | |
功能:根据概率,在水平或者垂直方向翻转图片
- p: 翻转概率
transforms.RandomHorizontalFlip(p=0.5),那么一半的图片会被水平翻转。
transforms.RandomHorizontalFlip(p=1),那么所有图片会被水平翻转。
transforms.RandomRotation
1 | |
功能:随机旋转图片
- degree: 旋转角度
- 当为 a 时,在 (-a, a) 之间随机选择旋转角度
- 当为 (a, b) 时,在 (a, b) 之间随机选择旋转角度
- resample: 重采样方法
- expand: 是否扩大矩形框,以保持原图信息。根据中心旋转点计算扩大后的图片。如果旋转点不是中心,即使设置 expand = True,还是会有部分信息丢失。
- center: 旋转点设置,是坐标,默认中心旋转。如设置左上角为:(0, 0)
图像变换
Pad
功能:对图像边缘进行填充1
torchvision.transforms.Pad(padding, fill=0, padding_mode='constant') - padding: 设置填充大小
- 当为 a 时,上下左右均填充 a 个像素
- 当为 (a, b) 时,左右填充 a 个像素,上下填充 b 个像素
- 当为 (a, b, c, d) 时,左上右下分别填充 a,b,c,d
- padding_mode: 填充模式,有 4 种模式,constant、edge、reflect、symmetric
- fill: 当 padding_mode 为 constant 时,设置填充的像素值,(R, G, B) 或者 (Gray)
torchvision.transforms.ColorJitter
功能:调整亮度、对比度、饱和度、色相。在照片的拍照过程中,可能会由于设备、光线问题,造成色彩上的偏差,因此需要调整这些属性,抵消这些因素带来的扰动。1
torchvision.transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)
- brightness: 亮度调整因子
- contrast: 对比度参数
- saturation: 饱和度参数
- brightness、contrast、saturation参数:当为 a 时,从 [max(0, 1-a), 1+a] 中随机选择;当为 (a, b) 时,从 [a, b] 中选择。
- hue: 色相参数
- num_output_channels: 输出的通道数。只能设置为 1 或者 3 (如果在后面使用了transforms.Normalize,则要设置为 3,因为transforms.Normalize只能接收 3 通道的输入)
1
torchvision.transforms.RandomGrayscale(p=0.1, num_output_channels=1) - p: 概率值,图像被转换为灰度图的概率
- num_output_channels: 输出的通道数。只能设置为 1 或者 3
功能:根据一定概率将图片转换为灰度图
transforms.RandomAffine
1 | |
功能:对图像进行仿射变换,仿射变换是 2 维的线性变换,由 5 种基本操作组成,分别是旋转、平移、缩放、错切和翻转。
- degree: 旋转角度设置
- translate: 平移区间设置,如 (a, b),a 设置宽 (width),b 设置高 (height)。图像在宽维度平移的区间为 $- img_width \times a < dx < img_width \times a$,高同理
- scale: 缩放比例,以面积为单位
- fillcolor: 填充颜色设置
- shear: 错切角度设置,有水平错切和垂直错切
- 若为 a,则仅在 x 轴错切,在 (-a, a) 之间随机选择错切角度
- 若为 (a, b),x 轴在 (-a, a) 之间随机选择错切角度,y 轴在 (-b, b) 之间随机选择错切角度
- 若为 (a, b, c, d),x 轴在 (a, b) 之间随机选择错切角度,y 轴在 (c, d) 之间随机选择错切角度
- resample: 重采样方式,有 NEAREST、BILINEAR、BICUBIC。
transforms.RandomErasing
功能:对图像进行随机遮挡。这个操作接收的输入是 tensor。因此在此之前需要先执行transforms.ToTensor()。同时注释掉后面的transforms.ToTensor()。1
torchvision.transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False) - p: 概率值,执行该操作的概率
- scale: 遮挡区域的面积。如(a, b),则会随机选择 (a, b) 中的一个遮挡比例
- ratio: 遮挡区域长宽比。如(a, b),则会随机选择 (a, b) 中的一个长宽比
- value: 设置遮挡区域的像素值。(R, G, B) 或者 Gray,或者任意字符串。由于之前执行了transforms.ToTensor(),像素值归一化到了 0~1 之间,因此这里设置的 (R, G, B) 要除以 255
transforms.Lambda
自定义 transform 方法。在上面的FiveCrop中就用到了transforms.Lambda。
1 | |
transforms.FiveCrop返回的是长度为 5 的 tuple,因此需要使用transforms.Lambda 把 tuple 转换为 4D 的 tensor。
transforms 的操作
torchvision.transforms.RandomChoice
1 | |
功能:从一系列 transforms 方法中随机选择一个
transforms.RandomApply
1 | |
功能:根据概率执行一组 transforms 操作,要么全部执行,要么全部不执行。
transforms.RandomOrder
1 | |
功能:对一组 transforms 操作打乱顺序
自定义transforms
自定义 transforms 有两个要素:仅接受一个参数,返回一个参数;注意上下游的输入与输出,上一个 transform 的输出是下一个 transform 的输入。
我们这里通过自定义 transforms 实现椒盐噪声。椒盐噪声又称为脉冲噪声,是一种随机出现的白点或者黑点,白点称为盐噪声,黑点称为椒噪声。信噪比 (Signal-Noise Rate,SNR) 是衡量噪声的比例,图像中正常像素占全部像素的占比。
我们定义一个AddPepperNoise类,作为添加椒盐噪声的 transform。在构造函数中传入信噪比和概率,在__call__()函数中执行具体的逻辑,返回的是 image。
1 | |
综合代码
1 | |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!