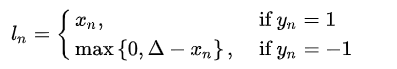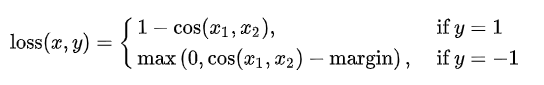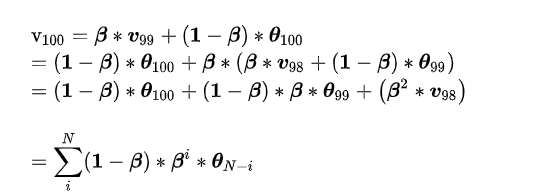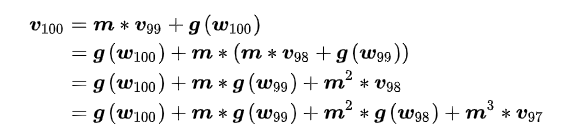本文最后更新于:2021年8月11日 下午
创作声明:主要内容参考于张贤同学https://zhuanlan.zhihu.com/p/265394674
权值初始化 在搭建好网络模型之后,一个重要的步骤就是对网络模型中的权值进行初始化。适当的权值初始化可以加快模型的收敛,而不恰当的权值初始化可能引发梯度消失或者梯度爆炸,最终导致模型无法收敛。下面分 3 部分介绍。第一部分介绍不恰当的权值初始化是如何引发梯度消失与梯度爆炸的,第二部分介绍常用的 Xavier 方法与 Kaiming 方法,第三部分介绍 PyTorch 中的 10 种初始化方法。
梯度消失与梯度爆炸 考虑一个 3 层的全连接网络。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import torchimport torch.nn as nnfrom common_tools import set_seedset_seed (1 ) # 设置随机种子class MLP (nn .Module ): def __init__(self , neural_num , layers ): super(MLP , self ).__init__() self.linears = nn.ModuleList ([nn .Linear (neural_num , neural_num , bias =False ) for i in range(layers )]) self.neural_num = neural_num def forward(self , x ): for (i , linear ) in enumerate(self .linears ): x = linear(x ) return x def initialize(self ): for m in self.modules(): # 判断这一层是否为线性层,如果为线性层则初始化权值 if isinstance(m , nn .Linear ): nn.init.normal_(m .weight .data ) # normal: mean=0, std=1 layer_nums = 100 neural_nums = 256 batch_size = 16 net = MLP (neural_nums , layer_nums ) net.initialize() inputs = torch.randn((batch_size , neural_nums )) # normal: mean=0, std=1 output = net(inputs ) print(output )
输出为:
1 2 3 4 5 6 7 tensor([[nan , nan , nan , ..., nan , nan , nan ],nan , nan , nan , ..., nan , nan , nan ],nan , nan , nan , ..., nan , nan , nan ],nan , nan , nan , ..., nan , nan , nan ],nan , nan , nan , ..., nan , nan , nan ],nan , nan , nan , ..., nan , nan , nan ]], grad_fn=<MmBackward>)
也就是数据太大(梯度爆炸)或者太小(梯度消失)了。接下来我们在forward()函数中判断每一次前向传播的输出的标准差是否为 nan,如果是 nan 则停止前向传播。
1 2 3 4 5 6 7 8 9 10 def forward(self, x ):in enumerate(self.linears):x = linear(x )rint( "layer:{}, std:{}" .format (i, x .std( )))if torch.isnan( x .std( )):rint( "output is nan in {} layers" .format (i))return x
输出如下:
1 2 3 4 5 6 7 8 9 10 layer: 0 , std :15.959932327270508 layer: 1 , std :256.6237487792969 layer: 2 , std :4107.24560546875 layer: 29 , std :1.322983152787379e+36 layer: 30 , std :2.0786820453988485e+37 layer: 31 , std :nanin 31 layers
可以看到每一层的标准差是越来越大的,并在在 31 层时超出了数据可以表示的范围。
$E(X \times Y)=E(X) \times E(Y)$:两个相互独立的随机变量的乘积的期望等于它们的期望的乘积。
$D(X)=E(X^{2}) - [E(X)]^{2}$:一个随机变量的方差等于它的平方的期望减去期望的平方
$D(X+Y)=D(X)+D(Y)$:两个相互独立的随机变量之和的方差等于它们的方差的和。
可以推导出两个随机变量的乘积的方差如下:
$D(X \times Y)=E[(XY)^{2}] - [E(XY)]^{2}=D(X) \times D(Y) + D(X) \times [E(Y)]^{2} + D(Y) \times [E(X)]^{2}$
如果$E(X)=0$,$E(Y)=0$,那么$D(X \times Y)=D(X) \times D(Y)$
我们以输入层第一个神经元为例:
$\mathrm{H}{11}=\sum{i=0}^{n} X{i} \times W{1 i}$
其中输入 X 和权值 W 都是服从$N(0,1)$的正态分布,所以这个神经元的方差为:
$\begin{aligned} \mathbf{D}\left(\mathrm{H}{11}\right) &=\sum{i=0}^{n} \boldsymbol{D}\left(X{i}\right) * \boldsymbol{D}\left(W{1 i}\right) \ &=n (1 1) \ &=n \end{aligned}$
标准差为:
$\operatorname{std}\left(\mathrm{H}{11}\right)=\sqrt{\mathbf{D}\left(\mathrm{H}{11}\right)}=\sqrt{n}$
所以每经过一个网络层,方差就会扩大 n 倍,标准差就会扩大$\sqrt{n}$倍,n 为每层神经元个数,直到超出数值表示范围。对比上面的代码可以看到,每层神经元个数为 256,输出数据的标准差为 1,所以第一个网络层输出的标准差为 16 左右,第二个网络层输出的标准差为 256 左右,以此类推,直到 31 层超出数据表示范围。可以把每层神经元个数改为 400,那么每层标准差扩大 20 倍左右。从$D(\mathrm{H}{11})=\sum{i=0}^{n} D(X{i}) \times D(W{1 i})$,可以看出,每一层网络输出的方差与神经元个数、输入数据的方差、权值方差有关,其中比较好改变的是权值的方差$D(W)$,所以$D(W)= \frac{1}{n}$,标准差为$std(W)=\sqrt\frac{1}{n}$。因此修改权值初始化代码为nn.init.normal_(m.weight.data, std=np.sqrt(1/self.neural_num)),结果如下:
1 2 3 4 5 6 7 8 9 layer: 0 , std :0.9974957704544067 layer: 1 , std :1.0024365186691284 layer: 2 , std :1.002745509147644 layer: 94 , std :1.031973123550415 layer: 95 , std :1.0413124561309814 layer: 96 , std :1.0817031860351562
修改之后,没有出现梯度消失或者梯度爆炸的情况,每层神经元输出的方差均在 1 左右。通过恰当的权值初始化,可以保持权值在更新过程中维持在一定范围之内,不过过大,也不会过小。
上述是没有使用非线性变换的实验结果,如果在forward()中添加非线性变换tanh,每一层的输出方差会越来越小,会导致梯度消失。因此出现了 Xavier 初始化方法与 Kaiming 初始化方法。
Xavier 方法 Xavier 是 2010 年提出的,针对有非线性激活函数时的权值初始化方法,目标是保持数据的方差维持在 1 左右,主要针对饱和激活函数如 sigmoid 和 tanh 等。同时考虑前向传播和反向传播,需要满足两个等式:$\boldsymbol{n}{\boldsymbol{i}} * \boldsymbol{D}(\boldsymbol{W})=\mathbf{1}$和$\boldsymbol{n}{\boldsymbol{i+1}} * \boldsymbol{D}(\boldsymbol{W})=\mathbf{1}$,可得:$D(W)=\frac{2}{n{i}+n{i+1}}$。
为了使 Xavier 方法初始化的权值服从均匀分布,假设$W$服从均匀分布$U[-a, a]$,那么方差 $D(W)=\frac{(-a-a)^{2}}{12}=\frac{(2 a)^{2}}{12}=\frac{a^{2}}{3}$,令$\frac{2}{n{i}+n{i+1}}=\frac{a^{2}}{3}$,解得:$\boldsymbol{a}=\frac{\sqrt{6}}{\sqrt{n{i}+n{i+1}}}$,所以$W$服从分布$U\left[-\frac{\sqrt{6}}{\sqrt{n{i}+n{i+1}}}, \frac{\sqrt{6}}{\sqrt{n{i}+n{i+1}}}\right]$
1 2 3 4 5 6 a = np.sqrt (6 / (self.neural_num + self.neural_num))'tanh' )a *= tanh_gaina , a )
并且每一层的激活函数都使用 tanh,输出如下:
1 2 3 4 5 6 7 8 9 layer: 0 , std :0.7571136355400085 layer: 1 , std :0.6924336552619934 layer: 2 , std :0.6677976846694946 layer: 97 , std :0.6426210403442383 layer: 98 , std :0.6407480835914612 layer: 99 , std :0.6442216038703918
可以看到每层输出的方差都维持在 0.6 左右。
PyTorch 也提供了 Xavier 初始化方法,可以直接调用:
1 2 tanh_gain = nn.init.calculate_gain('tanh ') _uniform_(m .weight .data , gain =tanh_gain )
nn.init.calculate_gain() 上面的初始化方法都使用了tanh_gain = nn.init.calculate_gain('tanh')。
1 nn.init.calculate_gain(nonlinearity ,param =** None** )
主要功能是计算经过一个分布的方差经过激活函数后的变化尺度,主要有两个参数:
nonlinearity:激活函数名称
param:激活函数的参数,如 Leaky ReLU 的 negative_slop。
下面是计算标准差经过激活函数的变化尺度的代码。
1 2 3 4 5 6 x = torch.randn( 10000) out = torch.tanh( x )x .std( ) / out .std( ) rint( 'gain:{}' .format (gain))in( 'tanh' ) rint( 'tanh_gain in PyTorch:' , tanh_gain)
输出如下:
1 2 gain :1 .5982500314712524 tanh_gain in PyTorch: 1 .6666666666666667
结果表示,原有数据分布的方差经过 tanh 之后,标准差会变小 1.6 倍左右。
Kaiming 方法 虽然 Xavier 方法提出了针对饱和激活函数的权值初始化方法,但是 AlexNet 出现后,大量网络开始使用非饱和的激活函数如 ReLU 等,这时 Xavier 方法不再适用。2015 年针对 ReLU 及其变种等激活函数提出了 Kaiming 初始化方法。
针对 ReLU,方差应该满足:$\mathrm{D}(W)=\frac{2}{n{i}}$;针对 ReLu 的变种,方差应该满足:$\mathrm{D}(W)=\frac{2}{n{i}}$,a 表示负半轴的斜率,如 PReLU 方法,标准差满足$\operatorname{std}(W)=\sqrt{\frac{2}{\left(1+a^{2}\right) * n{i}}}$。
代码如下:
1 nn.init .normal (m.weight .data , std=np.sqrt (2 / self.neuralnum))
或者使用 PyTorch 提供的初始化方法:
1 nn.init.kaiming_normal(m .weight .data )
同时把激活函数改为 ReLU。
常用初始化方法 PyTorch 中提供了 10 种初始化方法
Xavier 均匀分布
Xavier 正态分布
Kaiming 均匀分布
Kaiming 正态分布
均匀分布
正态分布
常数分布
正交矩阵初始化
单位矩阵初始化
稀疏矩阵初始化
每种初始化方法都有它自己使用的场景,原则是保持每一层输出的方差不能太大,也不能太小。
损失函数 损失函数是衡量模型输出与真实标签之间的差异。我们还经常听到代价函数和目标函数,它们之间差异如下:
损失函数(Loss Function)是计算一个 样本的模型输出与真实标签的差异
Loss $=f\left(y^{\wedge}, y\right)$
代价函数(Cost Function)是计算整个样本集的模型输出与真实标签的差异,是所有样本损失函数的平均值
$\cos t=\frac{1}{N} \sum_{i}^{N} f\left(y_{i}^{\wedge}, y_{i}\right)$
目标函数(Objective Function)就是代价函数加上正则项
在 PyTorch 中的损失函数也是继承于nn.Module,所以损失函数也可以看作网络层。
在逻辑回归的实验中,我使用了交叉熵损失函数loss_fn = nn.BCELoss(),$BCELoss$的继承关系:nn.BCELoss() -> _WeightedLoss -> _Loss -> Module。在计算具体的损失时loss = loss_fn(y_pred.squeeze(), train_y),这里实际上在 Loss 中进行一次前向传播,最终调用BCELoss()的forward()函数F.binary_cross_entropy(input, target, weight=self.weight, reduction=self.reduction)。
下面介绍 PyTorch 提供的损失函数。注意在所有的损失函数中,size_average和reduce参数都不再使用。
nn.CrossEntropyLoss nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
功能:把nn.LogSoftmax()和nn.NLLLoss()结合,计算交叉熵。nn.LogSoftmax()的作用是把输出值归一化到了 [0,1] 之间。
主要参数:
weight:各类别的 loss 设置权值
ignore_index:忽略某个类别的 loss 计算
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
下面介绍熵的一些基本概念
自信息:$\mathrm{I}(x)=-\log [p(x)]$
信息熵就是求自信息的期望:$\mathrm{H}(\mathrm{P})=E_{x \sim p}[I(x)]=-\sum_{i}^{N} P\left(x_{i}\right) \log P\left(x_{i}\right)$
相对熵,也被称为 KL 散度,用于衡量两个分布的相似性(距离):
交叉熵:$\mathrm{H}(\boldsymbol{P}, \boldsymbol{Q})=-\sum_{i=1}^{N} \boldsymbol{P}\left(\boldsymbol{x}_{i}\right) \log \boldsymbol{Q}\left(\boldsymbol{x}_{i}\right)$
相对熵展开可得:
所以交叉熵 = 信息熵 + 相对熵,即$\mathrm{H}(\boldsymbol{P}, \boldsymbol{Q})=\boldsymbol{D}{K \boldsymbol{L}}(\boldsymbol{P}, \boldsymbol{Q})+\mathrm{H}(\boldsymbol{P})$,又由于信息熵$H(P)$是固定的,因此优化交叉熵$H(P,Q)$等价于优化相对熵$D{KL}(P,Q)$。
所以对于每一个样本 的 Loss 计算公式为:
所以$\operatorname{loss}(x, \text { class })=-\log \left(\frac{\exp (x[\text { class }])}{\sum_{j} \exp (x[j])}\right)=-x[\text { class }]+\log \left(\sum_{j} \exp (x[j])\right)$。
如果了解类别的权重,则$\operatorname{loss}(x, \text { class })=\operatorname{weight}[\text { class }]\left(-x[\text { class }]+\log \left(\sum_{j} \exp (x[j])\right)\right)$。torch.long。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import torchas nnas Fas np[[1 , 2 ] , [1 , 3 ] , [1 , 3 ] ], dtype=torch.float )[0 , 1 , 1 ] , dtype=torch.long)function CrossEntropyLoss(weight =None, reduction ='none ') CrossEntropyLoss(weight =None, reduction ='sum ') CrossEntropyLoss(weight =None, reduction ='mean ') _f_none(inputs , target ) _f_sum(inputs , target ) _f_mean(inputs , target ) "Cross Entropy Loss:\n " , loss_none, loss_sum, loss_mean)
输出为:
1 2 Cross Entropy Loss:tensor ([1 .3133 , 0 .1269 , 0 .1269 ]) tensor(1 .5671 ) tensor(0 .5224 )
我们根据单个样本的 loss 计算公式$\operatorname{loss}(x, \text { class })=-\log \left(\frac{\exp (x[\text { class }])}{\sum_{j} \exp (x[j])}\right)=-x[\text { class }]+\log \left(\sum_{j} \exp (x[j])\right)$,可以使用以下代码来手动计算第一个样本的损失
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 idx = 0 input_1 = inputs.detach().numpy()[idx] target_1 = target.numpy()[idx] x_class = input_1[target_1]sigma_exp_x = np.sum(list(map (np.exp, input_1)))log_sigma_exp_x = np.log(sigma_exp_x)loss_1 = -x_class + log_sigma_exp_x"第一个样本loss为: " , loss_1)
结果为:1.3132617
下面继续看带有类别权重的损失计算,首先设置类别的权重向量weights = torch.tensor([1, 2], dtype=torch.float),向量的元素个数等于类别的数量,然后在定义损失函数时把weight参数传进去。
输出为:
1 2 weights : tensor([1 ., 2 .])tensor ([1 .3133 , 0 .2539 , 0 .2539 ]) tensor(1 .8210 ) tensor(0 .3642 )
权值总和为:$1+2+2=5$,所以加权平均的 loss 为:$1.8210\div5=0.3642$,通过手动计算的方式代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 weights = torch.tensor([1 , 2 ], dtype=torch.float) weights_all = np.sum(list(map (lambda x: weights.numpy()[x], target.numpy()))) mean = 0 loss_f_none = nn.CrossEntropyLoss(reduction='none') loss_none = loss_f_none(inputs, target)loss_sep = loss_none.detach().numpy()in range(target.shape[0 ]):x_class = target.numpy()[i]tmp = loss_sep[i] * (weights.numpy()[x_class] / weights_all)
结果为 0.3641947731375694
nn.NLLLoss 1 nn.NLLLoss(weight =None, size_average =None, ignore_index =-100, reduce =None, reduction ='mean' )
功能:实现负对数似然函数中的符号功能
主要参数:
weight:各类别的 loss 权值设置
ignore_index:忽略某个类别
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
每个样本的 loss 公式为:$l_{n}=-w_{y_{n}} x_{n, y_{n}}$。还是使用上面的例子,第一个样本的输出为 [1,2],类别为 0,则第一个样本的 loss 为 -1;第一个样本的输出为 [1,3],类别为 1,则第一个样本的 loss 为 -3。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 weights = torch.tensor([1 , 1 ] , dtype=torch.float )NLLLoss(weight =weights , reduction ='none ') NLLLoss(weight =weights , reduction ='sum ') NLLLoss(weight =weights , reduction ='mean ') _f_none_w(inputs , target ) _f_sum(inputs , target ) _f_mean(inputs , target ) "\nweights: " , weights)"NLL Loss" , loss_none_w, loss_sum, loss_mean)
输出如下:
1 2 weights : tensor([1 ., 1 .])NLL Loss tensor([-1 ., -3 ., -3 .]) tensor(-7 .) tensor(-2 .3333 )
nn.BCELoss 1 nn.BCELoss(weight =None, size_average =None, reduce =None, reduction ='mean' )
功能:计算二分类的交叉熵。需要注意的是:输出值区间为 [0,1]。
主要参数:
weight:各类别的 loss 权值设置
ignore_index:忽略某个类别
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
计算公式为:$l_{n}=-w_{n}\left[y_{n} \cdot \log x_{n}+\left(1-y_{n}\right) \cdot \log \left(1-x_{n}\right)\right]$
使用这个函数有两个不同的地方:
预测的标签需要经过 sigmoid 变换到 [0,1] 之间。
真实的标签需要转换为 one hot 向量,类型为torch.float。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 inputs = torch.tensor([[1, 2], [2, 2], [3, 4], [4, 5]], dtype =torch.float)dtype =torch.float)dtype =torch.float)weight =weights, reduction ='none' )weight =weights, reduction ='sum' )weight =weights, reduction ='mean' )print ("\nweights: " , weights)print ("BCE Loss" , loss_none_w, loss_sum, loss_mean)
结果为:
1 2 3 4 BCE Loss tensor(
第一个 loss 为 0,3133,手动计算的代码如下:
1 2 3 4 5 6 x_i = inputs.detach().numpy()[idx, idx]np .log (x_i) + (1 -y_i) * np .log (1 -y_i) ] # np .log (0 ) = nannp .log (x_i) if y_i else -(1 -y_i) * np .log (1 -x_i)
nn.BCEWithLogitsLoss 1 nn.BCEWithLogitsLoss(weight =None, size_average =None, reduce =None, reduction ='mean' , pos_weight =None)
功能:结合 sigmoid 与二分类交叉熵。需要注意的是,网络最后的输出不用经过 sigmoid 函数。这个 loss 出现的原因是有时网络模型最后一层输出不希望是归一化到 [0,1] 之间,但是在计算 loss 时又需要归一化到 [0,1] 之间。
主要参数:
weight:各类别的 loss 权值设置
pos_weight:设置样本类别对应的神经元的输出的 loss 权值
ignore_index:忽略某个类别
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 inputs = torch.tensor([[1, 2], [2, 2], [3, 4], [4, 5]], dtype =torch.float)dtype =torch.float)dtype =torch.float)dtype =torch.float) # 3weight =weights, reduction ='none' , pos_weight =pos_w)weight =weights, reduction ='sum' , pos_weight =pos_w)weight =weights, reduction ='mean' , pos_weight =pos_w)print ("\npos_weights: " , pos_w)print (loss_none_w, loss_sum, loss_mean)
输出为
1 2 3 4 5 pos_weights: tensor()
与 BCELoss 进行对比
1 2 3 4 BCE Loss tensor(
可以看到,样本类别对应的神经元的输出的 loss 都增加了 3 倍。
nn.L1Loss 1 nn.L1Loss(size_average =None, reduce =None, reduction ='mean' )
功能:计算 inputs 与 target 之差的绝对值
主要参数:
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
公式:$l_{n}=\left|x_{n}-y_{n}\right|$
nn.MSELoss 功能:计算 inputs 与 target 之差的平方
公式:$l_{n}=\left(x_{n}-y_{n}\right)^{2}$
主要参数:
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 inputs = torch.ones((2 , 2 ))2 , 2 )) * 3 L1Loss(reduction ='none ') _f(inputs , target ) "input:{}\ntarget:{}\nL1 loss:{}" .format(inputs, target, loss))6 MSE loss ----------------------------------------------MSELoss(reduction ='none ') _f_mse(inputs , target ) "MSE loss:{}" .format(loss_mse))
输出如下:
1 2 3 4 5 6 7 8 input :tensor([[1., 1.], [1., 1.]] )[[3., 3.], [3., 3.]] )[[2., 2.], [2., 2.]] )[[4., 4.], [4., 4.]] )
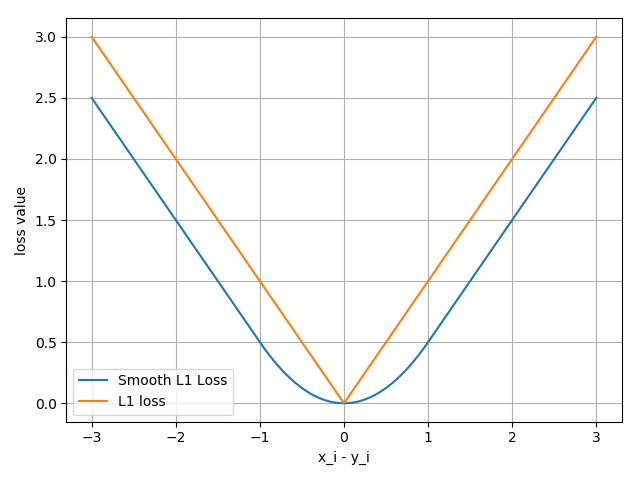
nn.SmoothL1Loss 1 nn.SmoothL1Loss(size_average =None, reduce =None, reduction ='mean' )
功能:平滑的 L1Loss
公式:
下图中橙色曲线是 L1Loss,蓝色曲线是 Smooth L1Loss
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
nn.PoissonNLLLoss 1 nn.PoissonNLLLoss(log_input =True , full =False , size_average =None, eps =1e-08, reduce =None, reduction ='mean' )
功能:泊松分布的负对数似然损失函数
主要参数:
log_input:输入是否为对数形式,决定计算公式
当 log_input = True,表示输入数据已经是经过对数运算之后的,loss(input, target) = exp(input) - target * input
当 log_input = False,,表示输入数据还没有取对数,loss(input, target) = input - target * log(input+eps)
full:计算所有 loss,默认为 loss
eps:修正项,避免 log(input) 为 nan
代码如下:
1 2 3 4 5 6 inputs = torch.randn((2, 2))log_input =True , full =False , reduction ='none' )print ("input:{}\ntarget:{}\nPoisson NLL loss:{}" .format(inputs, target, loss))
输出如下:
1 2 3 4 5 6 input :tensor([[0.6614, 0.2669], [0.0617, 0.6213]] )[[-0.4519, -0.1661], [-1.5228, 0.3817]] )[[2.2363, 1.3503], [1.1575, 1.6242]] )
手动计算第一个 loss 的代码如下:
1 2 3 4 5 idx = 0 .exp (inputs[idx, idx] ) - target[idx, idx] *inputs[idx, idx] print ("第一个元素loss:" , loss_1)
结果为:2.2363
nn.KLDivLoss 1 nn.KLDivLoss(size_average =None, reduce =None, reduction ='mean' )
功能:计算 KLD(divergence),KL 散度,相对熵
注意事项:需要提前将输入计算 log-probabilities,如通过nn.logsoftmax()
主要参数:
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量),batchmean(batchsize 维度求平均值)
公式:$\begin{aligned} D_{K L}(P | Q)=E_{x-p}\left[\log \frac{P(x)}{Q(x)}\right] &=E_{x-p}[\log P(x)-\log Q(x)] =\sum_{i=1}^{N} P\left(x_{i}\right)\left(\log P\left(x_{i}\right)-\log Q\left(x_{i}\right)\right) \end{aligned}$
对于每个样本来说,计算公式如下,其中$y_{n}$是真实值$P(x)$,$x_{n}$是经过对数运算之后的预测值$logQ(x)$。
$l_{n}=y_{n} \cdot\left(\log y_{n}-x_{n}\right)$
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 inputs = torch.tensor([[0.5 , 0.3 , 0.2 ] , [0.2 , 0.3 , 0.5 ] ])[[0.9 , 0.05 , 0.05 ] , [0.1 , 0.7 , 0.2 ] ], dtype=torch.float )KLDivLoss(reduction ='none ') KLDivLoss(reduction ='mean ') KLDivLoss(reduction ='batchmean ') _f_none(inputs , target ) _f_mean(inputs , target ) _f_bs_mean(inputs , target ) "loss_none:\n{}\nloss_mean:\n{}\nloss_bs_mean:\n{}" .format(loss_none, loss_mean, loss_bs_mean))
输出如下:
1 2 3 4 5 6 7 loss_none:-0 .5448, -0 .1648, -0 .1598],-0 .2503, -0 .4597, -0 .4219]])-0 .3335360586643219-1 .000608205795288
手动计算第一个 loss 的代码为:
1 2 3 idx = 0 target [idx, idx] * (torch.log (target [idx, idx]) - inputs[idx, idx])print ("第一个元素loss:" , loss_1)
结果为:-0.5448。
nn.MarginRankingLoss 1 nn.MarginRankingLoss(margin =0.0, size_average =None, reduce =None, reduction ='mean' )
功能:计算两个向量之间的相似度,用于排序任务
特别说明:该方法计算 两组数据之间的差异,返回一个$n \times n$ 的 loss 矩阵
主要参数:
margin:边界值,$x_{1}$与$x_{2}$之间的差异值
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
计算公式:$\operatorname{loss}(x, y)=\max (0,-y *(x 1-x 2)+\operatorname{margin})$,$y$的取值有 +1 和 -1。
当 $y=1$时,希望$x_{1} > x_{2}$,当$x_{1} > x_{2}$,不产生 loss
当 $y=-1$时,希望$x_{1} < x_{2}$,当$x_{1} < x_{2}$,不产生 loss
代码如下:
1 2 3 4 5 6 7 8 9 10 x1 = torch.tensor ([[1] , [2] , [3] ], dtype=torch.float ).tensor ([[2] , [2] , [2] ], dtype=torch.float ).tensor ([1, 1, -1] , dtype=torch.float ).MarginRankingLoss (margin =0 , reduction='none' )print (loss)
输出为:
1 2 3 tensor([[1., 1., 0.], [0., 0., 0.], [0., 0., 1.]] )
第一行表示$x_{1}$中的第一个元素分别与$x_{2}$中的 3 个元素计算 loss,以此类推。
nn.MultiLabelMarginLoss 1 nn.MultiLabelMarginLoss(size_average =None, reduce =None, reduction ='mean' )
功能:多标签边界损失函数
举例:4 分类任务,样本 x 属于 0 类和 3 类,那么标签为 [0, 3, -1, -1],
主要参数:
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
计算公式:$\operatorname{loss}(x, y)=\sum_{i j} \frac{\max (0,1-(x[y[j]]-x[i]))}{x \cdot \operatorname{size}(0)}$,表示每个真实类别的神经元输出减去其他神经元的输出。
代码如下:
1 2 3 4 5 6 7 8 x = torch.tensor([[0 .1 , 0 .2 , 0 .4 , 0 .8 ]])y = torch.tensor([[0 , 3 , -1 , -1 ]], dtype=torch.long)loss_f = nn.MultiLabelMarginLoss(reduction='none')loss = loss_f(x, y)print (loss)
输出为:
手动计算如下:
1 2 3 4 5 6 7 x = x[0 ]item_1 = (1 -(x[0 ] - x[1 ])) + (1 - (x[0 ] - x[2 ])) # [0] item_2 = (1 -(x[3 ] - x[1 ])) + (1 - (x[3 ] - x[2 ])) # [3] loss_h = (item_1 + item_2 ) / x.shape[0 ]print (loss_h)
nn.SoftMarginLoss 1 nn.SoftMarginLoss(size_average =None, reduce =None, reduction ='mean' )
功能:计算二分类的 logistic 损失
主要参数:
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
计算公式:$\operatorname{loss}(x, y)=\sum_{i} \frac{\log (1+\exp (-y[i] * x[i]))}{\text { x.nelement } 0}$
代码如下:
1 2 3 4 5 6 7 8 inputs = torch.tensor([[0.3, 0.7], [0.5, 0.5]] )[[-1, 1], [1, -1]] , dtype=torch.float)'none' )print ("SoftMargin: " , loss)
输出如下:
1 2 SoftMargin: tensor([[0.8544, 0.4032], [0.4741, 0.9741]] )
手动计算第一个 loss 的代码如下:
1 2 3 4 5 6 7 8 idx = 0 np .log (1 + np .exp (-target_i * inputs_i))print (loss_h)
结果为:0.8544
nn.MultiLabelSoftMarginLoss 1 nn.MultiLabelSoftMarginLoss(weight =None, size_average =None, reduce =None, reduction ='mean' )
功能:SoftMarginLoss 的多标签版本
主要参数:
weight:各类别的 loss 权值设置
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
计算公式:$\operatorname{loss}(x, y)=-\frac{1}{C} \sum_{i} y[i] \log \left((1+\exp (-x[i]))^{-1}\right)+(1-y[i]) * \log \left(\frac{\exp (-x[i])}{(1+\exp (-x[i]))}\right)$
代码如下
1 2 3 4 5 6 7 8 inputs = torch.tensor([[0.3, 0.7, 0.8]] )[[0, 1, 1]] , dtype=torch.float)'none' )print ("MultiLabel SoftMargin: " , loss)
输出为:
1 MultiLabel SoftMargin: tensor([0 .5429 ])
手动计算的代码如下:
1 2 3 4 5 6 7 8 x = torch.tensor ([[0.1, 0.2, 0.7] , [0.2, 0.5, 0.3] ]).tensor ([1, 2] , dtype=torch.long).MultiMarginLoss (reduction='none' )print ("Multi Margin Loss: " , loss)
nn.MultiMarginLoss 1 nn.MultiMarginLoss(p =1, margin =1.0, weight =None, size_average =None, reduce =None, reduction ='mean' )
功能:计算多分类的折页损失
主要参数:
p:可以选择 1 或 2
weight:各类别的 loss 权值设置
margin:边界值
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
计算公式:$\operatorname{loss}(x, y)=\frac{\left.\sum_{i} \max (0, \operatorname{margin}-x[y]+x[i])\right)^{p}}{\quad \text { x.size }(0)}$,其中 y 表示真实标签对应的神经元输出,x 表示其他神经元的输出。
代码如下:
1 2 3 4 5 6 7 8 x = torch.tensor ([[0.1, 0.2, 0.7] , [0.2, 0.5, 0.3] ]).tensor ([1, 2] , dtype=torch.long).MultiMarginLoss (reduction='none' )print ("Multi Margin Loss: " , loss)
输出如下:
1 Multi Margin Loss: tensor([0 .8000 , 0 .7000 ])
手动计算第一个 loss 的代码如下:
1 2 3 4 5 6 7 8 9 10 x = x[0 ]margin = 1 i_0 = margin - (x[1 ] - x[0 ])i_2 = margin - (x[1 ] - x[2 ])loss_h = (i_0 + i_2 ) / x.shape[0 ]print (loss_h)
输出为:0.8000
nn.TripletMarginLoss 1 nn.TripletMarginLoss(margin =1.0, p =2.0, eps =1e-06, swap =False , size_average =None, reduce =None, reduction ='mean' )
功能:计算三元组损失,人脸验证中常用
主要参数:
p:范数的阶,默认为 2
margin:边界值
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
计算公式:
代码如下:
1 2 3 4 5 6 7 8 9 anchor = torch.tensor([[1.]] )[[2.]] )[[0.5]] )1.0 , p=1 )print ("Triplet Margin Loss" , loss)
输出如下:
1 Triplet Margin Loss tensor(1 .5000 )
手动计算的代码如下:
1 2 3 4 5 6 7 8 9 margin = 1 a , p , n = anchor[0] , pos[0] , neg[0] .abs (a-p).abs (a-n)margin print (loss)
nn.HingeEmbeddingLoss 1 nn.HingeEmbeddingLoss(margin =1.0, size_average =None, reduce =None, reduction ='mean' )
功能:计算两个输入的相似性,常用于非线性 embedding 和半监督学习
特别注意:输入 x 应该为两个输入之差的绝对值
主要参数:
margin:边界值
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
计算公式:
!
代码如下:
1 2 3 4 5 6 7 8 inputs = torch.tensor([[1., 0.8, 0.5]] )[[1, 1, -1]] )1 , reduction='none' )print ("Hinge Embedding Loss" , loss)
输出为:
1 Hinge Embedding Loss tensor([[1 .0000 , 0 .8000 , 0 .5000 ]])
手动计算第三个 loss 的代码如下:
1 2 3 4 margin = 1 .loss = max(0 , margin - inputs.numpy()[0 , 2 ])print (loss)
结果为 0.5
nn.CosineEmbeddingLoss 1 torch.nn.CosineEmbeddingLoss(margin =0.0, size_average =None, reduce =None, reduction ='mean' )
功能:采用余弦相似度计算两个输入的相似性
主要参数:
margin:边界值,可取值 [-1, 1],推荐为 [0, 0.5]
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
计算公式:
其中$\cos (\theta)=\frac{A \cdot B}{|A||B|}=\frac{\sum_{i=1}^{n} A_{i} \times B_{i}}{\sqrt{\sum_{i=1}^{n}\left(A_{i}\right)^{2}} \times \sqrt{\sum_{i=1}^{n}\left(B_{i}\right)^{2}}}$
代码如下:
1 2 3 4 5 6 7 8 9 10 x1 = torch.tensor([[0.3, 0.5, 0.7], [0.3, 0.5, 0.7]] )[[0.1, 0.3, 0.5], [0.1, 0.3, 0.5]] )[[1, -1]] , dtype=torch.float)0. , reduction='none' )print ("Cosine Embedding Loss" , loss)
输出如下:
1 Cosine Embedding Loss tensor([[0.0167, 0.9833]] )
手动计算第一个样本的 loss 的代码为:
1 2 3 4 5 6 7 8 9 10 11 12 margin = 0 .def cosine(a, b):numerator = torch.dot(a, b)denominator = torch.norm(a, 2 ) * torch.norm(b, 2 )return float(numerator/denominator)l_1 = 1 - (cosine(x1 [0 ], x2 [0 ]))l_2 = max(0 , cosine(x1 [0 ], x2 [0 ]))print (l_1 , l_2 )
结果为:0.016662120819091797 0.9833378791809082
nn.CTCLoss 1 nn.CTCLoss(blank =0, reduction ='mean' , zero_infinity =False )
功能:计算 CTC 损失,解决时序类数据的分类,全称为 Connectionist Temporal Classification
主要参数:
blank:blank label
zero_infinity:无穷大的值或梯度置 0
reduction:计算模式,可以为 none(逐个元素计算),sum(所有元素求和,返回标量),mean(加权平均,返回标量)
对时序方面研究比较少,不展开讲了。
优化器 PyTorch 中的优化器是用于管理并更新模型中可学习参数的值,使得模型输出更加接近真实标签。
optimizer 的属性 PyTorch 中提供了 Optimizer 类,定义如下:
1 2 3 4 5 class Optimizer(object):self , params, defaults): self .defaults = defaultsself .state = defaultdict(dict)self .param_groups = []
主要有 3 个属性
defaults:优化器的超参数,如 weight_decay,momentum
state:参数的缓存,如 momentum 中需要用到前几次的梯度,就缓存在这个变量中
param_groups:管理的参数组,是一个 list,其中每个元素是字典,包括 momentum、lr、weight_decay、params 等。
_step_count:记录更新 次数,在学习率调整中使用
optimizer 的方法
zero_grad():清空所管理参数的梯度。由于 PyTorch 的特性是张量的梯度不自动清零,因此每次反向传播之后都需要清空梯度。代码如下:
1 2 3 4 5 6 7 def zero_grad (self ):r"""Clears the gradients of all optimized :class:`torch.Tensor` s.""" for group in self.param_groups:for p in group['params' ]:if p.grad is not None :
step():执行一步梯度更新
add_param_group():添加参数组,主要代码如下:
1 2 3 4 5 6 def add_param_group (self, param_group ): params = param_group['params' ]if isinstance (params , torch.Tensor param_group['params '] = [params ]
state_dict():获取优化器当前状态信息字典
load_state_dict():加载状态信息字典,包括 state 、momentum_buffer 和 param_groups。主要用于模型的断点续训练。我们可以在每隔 50 个 epoch 就保存模型的 state_dict 到硬盘,在意外终止训练时,可以继续加载上次保存的状态,继续训练。代码如下:
1 2 3 4 5 6 7 def state_dict(self):"" return {'state' : packed_state,'param_groups' : param_groups,
下面是代码示例:
step() 张量 weight 的形状为$2 \times 2$,并设置梯度为 1,把 weight 传进优化器,学习率设置为 1,执行optimizer.step()更新梯度,也就是所有的张量都减去 1。
1 2 3 4 5 6 7 weight = torch.randn((2, 2), requires_grad =True )lr =1)print ("weight before step:{}" .format(weight.data))step () # 修改lr =1, 0.1观察结果print ("weight after step:{}" .format(weight.data))
输出为:
1 2 3 4 weight before step:tensor([[0.6614, 0.2669], [0.0617, 0.6213]] )[[-0.3386, -0.7331], [-0.9383, -0.3787]] )
zero_grad() 代码如下:
1 2 3 4 5 6 7 8 9 print ("weight before step:{}" .format (weight.data))print ("weight after step:{}" .format (weight.data))print ("weight in optimizer:{}\nweight in weight:{}\n" .format (id (optimizer.param_groups[0 ]['params' ][0 ]), id (weight)))print ("weight.grad is {}\n" .format (weight.grad))print ("after optimizer.zero_grad(), weight.grad is\n{}" .format (weight.grad))
输出为:
1 2 3 4 5 6 7 8 9 10 11 weight before step:tensor([[0.6614, 0.2669], [0.0617, 0.6213]] )[[-0.3386, -0.7331], [-0.9383, -0.3787]] )in optimizer:1932450477472 in weight:1932450477472 [[1., 1.], [1., 1.]] )[[0., 0.], [0., 0.]] )
可以看到优化器的 param_groups 中存储的参数和 weight 的内存地址是一样的,所以优化器中保存的是参数的地址,而不是把参数复制到优化器中。
add_param_group() 向优化器中添加一组参数,代码如下:
1 2 3 4 print ("optimizer.param_groups is\n{}" .format(optimizer.param_groups) .randn ((3 , 3 ), requires_grad=True).add_param_group ({"params" : w2, 'lr' : 0.0001 })print ("optimizer.param_groups is\n{}" .format(optimizer.param_groups)
输出如下:
1 2 3 4 5 6 7 8 optimizer.param_groups is'params' : [tensor([[0.6614, 0.2669], [0.0617, 0.6213]] , requires_grad=True)], 'lr' : 1 , 'momentum' : 0 , 'dampening' : 0 , 'weight_decay' : 0 , 'nesterov' : False}]'params' : [tensor([[0.6614, 0.2669], [0.0617, 0.6213]] , requires_grad=True)], 'lr' : 1 , 'momentum' : 0 , 'dampening' : 0 , 'weight_decay' : 0 , 'nesterov' : False}, {'params' : [tensor([[-0.4519, -0.1661, -1.5228], [ 0.3817, -1.0276, -0.5631], [-0.8923, -0.0583, -0.1955]] , requires_grad=True)], 'lr' : 0.0001 , 'momentum' : 0 , 'dampening' : 0 , 'weight_decay' : 0 , 'nesterov' : False}]
state_dict() 首先进行 10 次反向传播更新,然后对比 state_dict 的变化。可以使用torch.save()把 state_dict 保存到 pkl 文件中。
1 2 3 4 5 6 7 8 9 10 11 optimizer = optim.SGD ([weight] , lr=0.1 , momentum=0.9 ).state_dict ()print ("state_dict before step:\n" , opt_state_dict) for i in range(10 ):.step ()print ("state_dict after step:\n" , optimizer.state_dict() .save (optimizer.state_dict (), os.path .join (BASE_DIR, "optimizer_state_dict.pkl" ))
输出为:
1 2 3 4 5 state_dict before step:'state' : {}, 'param_groups' : [{'lr' : 0.1 , 'momentum' : 0.9 , 'dampening' : 0 , 'weight_decay' : 0 , 'nesterov' : False , 'params' : [1976501036448 ]}]}'state' : {1976501036448 : {'momentum_buffer' : tensor([[6.5132 , 6.5132 ],6.5132 , 6.5132 ]])}}, 'param_groups' : [{'lr' : 0.1 , 'momentum' : 0.9 , 'dampening' : 0 , 'weight_decay' : 0 , 'nesterov' : False , 'params' : [1976501036448 ]}]}
经过反向传播后,state_dict 中的字典保存了1976501036448作为 key,这个 key 就是参数的内存地址。
load_state_dict() 上面保存了 state_dict 之后,可以先使用torch.load()把加载到内存中,然后再使用load_state_dict()加载到模型中,继续训练。代码如下:
1 2 3 4 5 6 optimizer = optim.SGD ([weight] , lr=0.1 , momentum=0.9 ).load (os.path .join (BASE_DIR, "optimizer_state_dict.pkl" ))print ("state_dict before load state:\n" , optimizer.state_dict() .load_state_dict (state_dict)print ("state_dict after load state:\n" , optimizer.state_dict()
输出如下:
1 2 3 4 5 state_dict before load state:'state' : {}, 'param_groups' : [{'lr' : 0.1 , 'momentum' : 0.9 , 'dampening' : 0 , 'weight_decay' : 0 , 'nesterov' : False, 'params' : [2075286132128 ]}]}load state:'state' : {2075286132128 : {'momentum_buffer' : tensor([[6.5132, 6.5132], [6.5132, 6.5132]] )}}, 'param_groups' : [{'lr' : 0.1 , 'momentum' : 0.9 , 'dampening' : 0 , 'weight_decay' : 0 , 'nesterov' : False, 'params' : [2075286132128 ]}]}
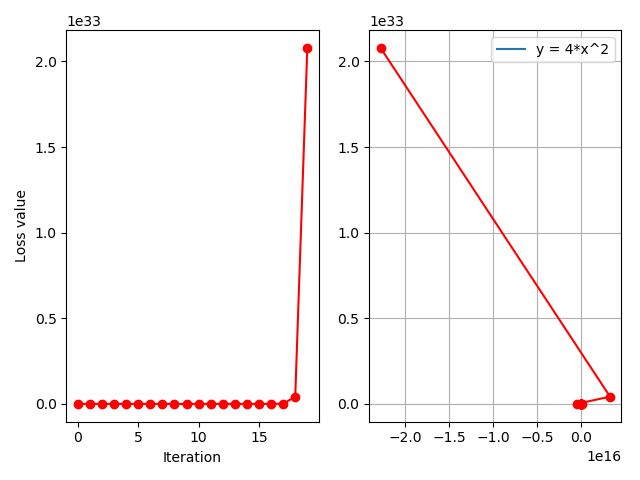
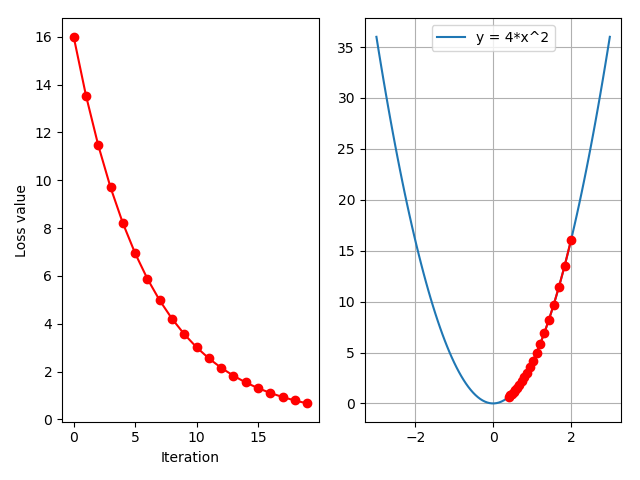
学习率 学习率是影响损失函数收敛的重要因素,控制了梯度下降更新的步伐。下面构造一个损失函数$y=(2x)^{2}$,$x$的初始值为 2,学习率设置为 1。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 iter_rec , loss_rec, x_rec = list(), list(), list()lr = 0 .01 # /1 . /.5 /.2 /.1 /.125 max_iteration = 20 # /1 . 4 /.5 4 /.2 20 200 for i in range(max_iteration):y = func(x)y .backward()print ("Iter:{}, X:{:8}, X.grad:{:8}, loss:{:10}" .format(i , x.detach().numpy()[0 ], x.grad.detach().numpy()[0 ], y.item()))x_rec .append(x.item())x .data.sub_(lr * x.grad) # x -= x.grad 数学表达式意义: x = x - x.grad # 0 .5 0 .2 0 .1 0 .125 x .grad.zero_()iter_rec .append(i)loss_rec .append(y)plt .subplot(121 ).plot(iter_rec, loss_rec, '-ro')plt .xlabel("Iteration" )plt .ylabel("Loss value" )x_t = torch.linspace(-3 , 3 , 100 )y = func(x_t)plt .subplot(122 ).plot(x_t.numpy(), y.numpy(), label="y = 4*x^2" )plt .grid()y_rec = [func(torch.tensor(i)).item() for i in x_rec] plt .subplot(122 ).plot(x_rec, y_rec, '-ro')plt .legend()plt .show()
结果如下:
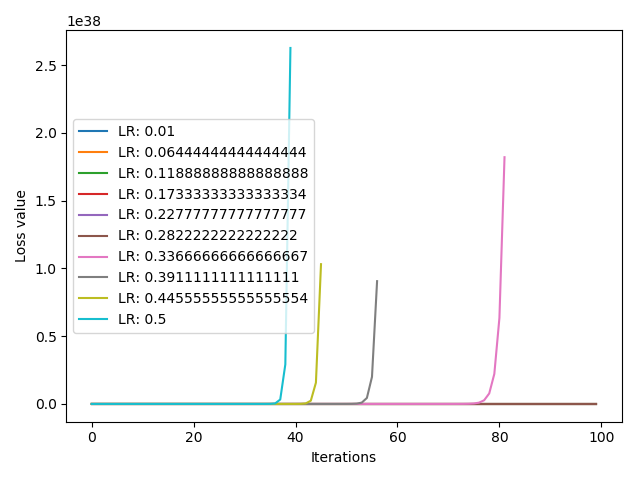
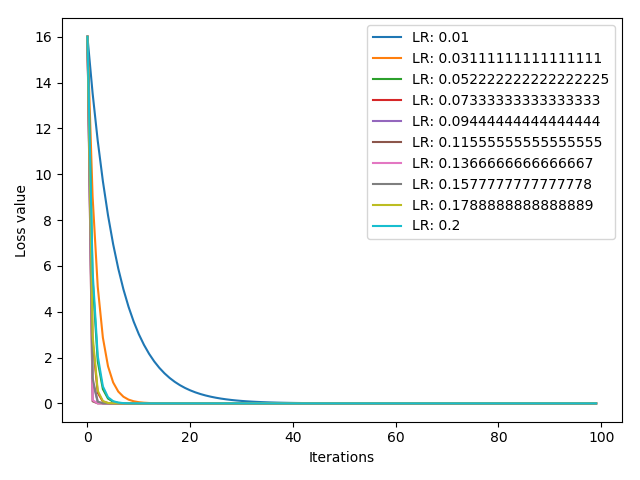
下面的代码是试验 10 个不同的学习率 ,[0.01, 0.5] 之间线性选择 10 个学习率,并比较损失函数的收敛情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 iteration = 100 10 0.01 , 0.2 for l in range (len (lr_list))]list ()for i, lr in enumerate (lr_list):2. ], requires_grad=True )for iter in range (iteration):for i, loss_r in enumerate (loss_rec):range (len (loss_r)), loss_r, label="LR: {}" .format (lr_list[i]))'Iterations' )'Loss value' )
结果如下:
momentum 动量 momentum 动量的更新方法,不仅考虑当前的梯度,还会结合前面的梯度。
momentum 来源于指数加权平均:$\mathrm{v}{t}=\boldsymbol{\beta} * \boldsymbol{v}{t-1}+(\mathbf{1}-\boldsymbol{\beta}) * \boldsymbol{\theta}{t}$,其中$v_{t-1}$是上一个时刻的指数加权平均,$\theta_{t}$表示当前时刻的值,$\beta$是系数,一般小于 1。指数加权平均常用于时间序列求平均值。假设现在求得是 100 个时刻的指数加权平均,那么
从上式可以看到,由于$\beta$小于1,越前面时刻的$\theta$,$\beta$的次方就越大,系数就越小。
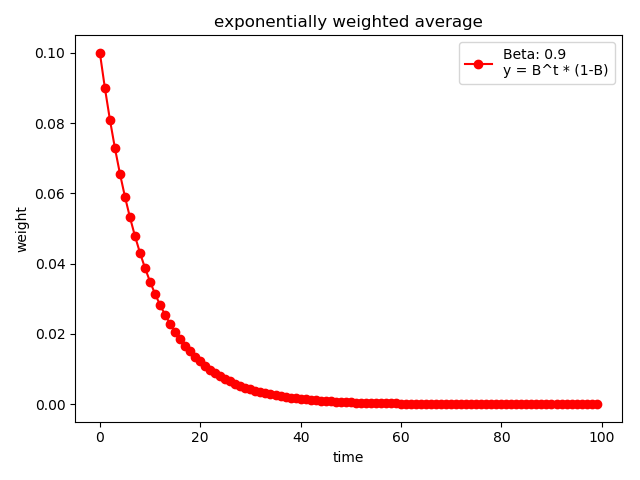
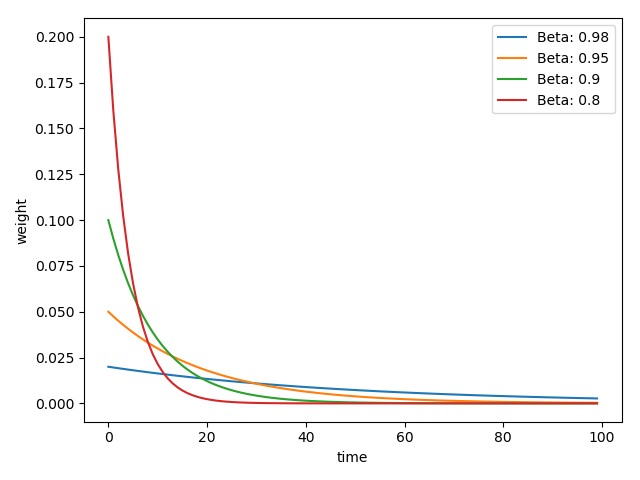
$\beta$ 可以理解为记忆周期,$\beta$越小,记忆周期越短,$\beta$越大,记忆周期越长。通常$\beta$设置为 0.9,那么 $\frac{1}{1-\beta}=\frac{1}{1-0.9}=10$,表示更关注最近 10 天的数据。
下面代码展示了$\beta=0.9$的情况
1 2 3 4 5 6 7 8 9 10 weights = exp_w_func(beta , time_list)label ="Beta: {}\ny = B^t * (1-B)" .format(beta ))xlabel ("time" )ylabel ("weight" )legend ()title ("exponentially weighted average" )show ()print (np .sum (weights))
结果为:
1 2 3 4 5 6 7 8 beta_list = [0.98, 0.95, 0.9, 0.8] [exp_w_func(beta, time_list) for beta in beta_list] for i , w in enumerate(w_list):.plot (time_list, w, label="Beta: {}" .format (beta_list[i] )).xlabel ("time" ).ylabel ("weight" ).legend ().show ()
结果为:
在 PyTroch 中,momentum 的更新公式是:
$v_{i}=m * v_{i-1}+g\left(w_{i}\right)$ $w_{i+1}=w_{i}-l r * v_{i}$
其中$w_{i+1}$表示第$i+1$次更新的参数,lr 表示学习率,$v_{i}$表示更新量,$m$表示 momentum 系数,$g(w_{i})$表示$w_{i}$的梯度。展开表示如下:
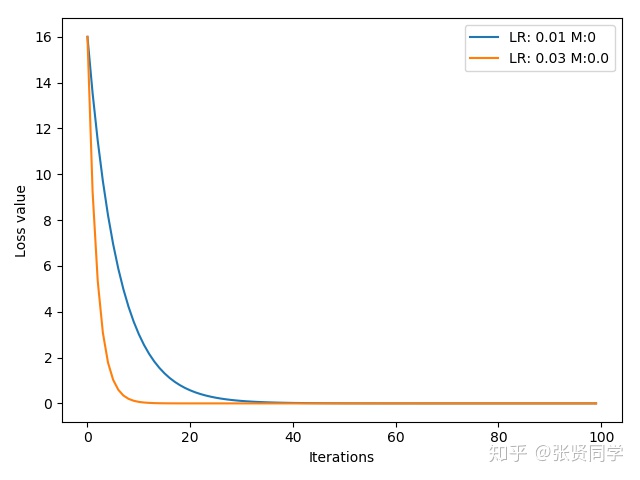
下面的代码是构造一个损失函数$y=(2x)^{2}$,$x$的初始值为 2,记录每一次梯度下降并画图,学习率使用 0.01 和 0.03,不适用 momentum。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 def func(x):pow (2 *x, 2 ) # y = (2 x)^2 = 4 *x^2 dy/dx = 8 x100 0 # .9 .63 0.01 , 0.03 ]list ()range (len (lr_list))]list ()enumerate (lr_list):tensor ([2 .], requires_grad=True)0 . if lr == 0.03 else mappend (momentum)SGD ([x], lr=lr, momentum=momentum)range (iteration):func (x)backward ()step ()zero_grad ()append (y.item ())enumerate (loss_rec):plot (range (len (loss_r)), loss_r, label="LR: {} M:{}" .format (lr_list[i], momentum_list[i]))legend ()xlabel ('Iterations' )ylabel ('Loss value' )show ()
结果为:
下面介绍 PyTroch 所提供的 10 种优化器。
PyTroch 提供的 10 种优化器 optim.SGD 1 optim.SGD(params, lr =<required parameter>, momentum =0, dampening =0, weight_decay =0, nesterov =False
随机梯度下降法
主要参数:
params:管理的参数组
lr:初始学习率
momentum:动量系数$\beta$
weight_decay:L2 正则化系数
nesterov:是否采用 NAG
optim.Adagrad 自适应学习率梯度下降法
optim.RMSprop Adagrad 的改进
optim.Adadelta optim.Adam RMSProp 集合 Momentum,这个是目前最常用的优化器,因为它可以使用较大的初始学习率。
optim.Adamax Adam 增加学习率上限
optim.SparseAdam 稀疏版的 Adam
optim.ASGD 随机平均梯度下降
optim.Rprop 弹性反向传播,这种优化器通常是在所有样本都一起训练,也就是 batchsize 为全部样本时使用。
optim.LBFGS BFGS 在内存上的改进
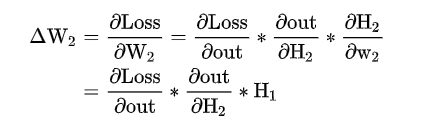
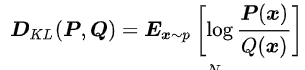 其中 P(X)是真实分布, Q(X)是拟合的分布
其中 P(X)是真实分布, Q(X)是拟合的分布
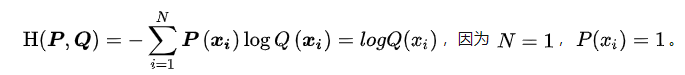
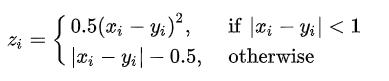
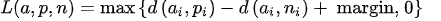 ,$d\left(x{i}, y{i}\right)=\left|\mathbf{x}{i}-\mathbf{y}{i}\right|{p}$,其中$d(a_{i}, p_{i})$表示正样本对之间的距离(距离计算公式与 p 有关),$d(a_{i}, n_{i})$表示负样本对之间的距离。表示正样本对之间的距离比负样本对之间的距离小 margin,就没有了 loss。
,$d\left(x{i}, y{i}\right)=\left|\mathbf{x}{i}-\mathbf{y}{i}\right|{p}$,其中$d(a_{i}, p_{i})$表示正样本对之间的距离(距离计算公式与 p 有关),$d(a_{i}, n_{i})$表示负样本对之间的距离。表示正样本对之间的距离比负样本对之间的距离小 margin,就没有了 loss。