本文最后更新于:2021年8月15日 下午
创作声明:主要内容参考于张贤同学https://zhuanlan.zhihu.com/p/265394674
PyTorch 中的模型保存与加载 序列化与反序列化 模型在内存中是以对象的逻辑结构保存的,但是在硬盘中是以二进制流的方式保存的。
序列化是指将内存中的数据以二进制序列的方式保存到硬盘中。PyTorch 的模型保存就是序列化。
反序列化是指将硬盘中的二进制序列加载到内存中,得到模型的对象。PyTorch 的模型加载就是反序列化。torch.save
1 torch.save(obj, f, pickle_module, pickle_protocol =2, _use_new_zipfile_serialization =False )
主要参数:
obj:保存的对象,可以是模型。也可以是 dict。因为一般在保存模型时,不仅要保存模型,还需要保存优化器、此时对应的 epoch 等参数。这时就可以用 dict 包装起来。
f:输出路径
其中模型保存还有两种方式:
保存整个 Module 这种方法比较耗时,保存的文件大
只保存模型的参数 推荐这种方法,运行比较快,保存的文件比较小
1 2 state_sict = net .state_dict()path )
下面是保存 LeNet 的例子。在网络初始化中,把权值都设置为 2020,然后保存模型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import torch.nn as nnfrom common_tools import set_seed.Module ):__init__ (self, classes):super (LeNet2, self).__init__ ()Sequential (Conv2d (3 , 6 , 5 ),ReLU (),MaxPool2d (2 , 2 ),Conv2d (6 , 16 , 5 ),ReLU (),MaxPool2d (2 , 2 )Sequential (Linear (16 *5 *5 , 120 ),ReLU (),Linear (120 , 84 ),ReLU (),Linear (84 , classes)forward (self, x):features (x)view (x.size ()[0 ], -1 )classifier (x)initialize (self):parameters ():fill_ (2020 )LeNet2 (classes=2019 )"训练" print ("训练前: " , net.features[0 ].weight[0 , ...])initialize ()print ("训练后: " , net.features[0 ].weight[0 , ...])"./model.pkl" "./model_state_dict.pkl" save (net, path_model)state_dict ()save (net_state_dict, path_state_dict)
运行完之后,文件夹中生成了```model.pkl``和model_state_dict.pkl,分别保存了整个网络和网络的参数
torch.load 1 torch.load (f, map_location=None , pickle_module, **pickle_load_args)
主要参数:
f:文件路径
map_location:指定存在 CPU 或者 GPU。
加载模型也有两种方式
加载整个 Module 如果保存的时候,保存的是整个模型,那么加载时就加载整个模型。这种方法不需要事先创建一个模型对象,也不用知道模型的结构,代码如下:
1 2 3 4 path_model = "./model.pkl" .load (path_model)print (net_load)
输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 LeNet2(kernel_size =2, stride =2, padding =0, dilation =1, ceil_mode =False )kernel_size =2, stride =2, padding =0, dilation =1, ceil_mode =False )in_features =400, out_features =120, bias =True )in_features =120, out_features =84, bias =True )in_features =84, out_features =2019, bias =True )
只加载模型的参数 如果保存的时候,保存的是模型的参数,那么加载时就参数。这种方法需要事先创建一个模型对象,再使用模型的load_state_dict()方法把参数加载到模型中,代码如下:
1 2 3 4 5 6 7 path_state_dict = "./model_state_dict.pkl" .load (path_state_dict)2019 )print ("加载前: " , net_new.features[0 ].weight[0 , ...]) .load_state_dict (state_dict_load)print ("加载后: " , net_new.features[0 ].weight[0 , ...])
模型的断点续训练 在训练过程中,可能由于某种意外原因如断点等导致训练终止,这时需要重新开始训练。断点续练是在训练过程中每隔一定次数的 epoch 就保存模型的参数和优化器的参数 ,这样如果意外终止训练了,下次就可以重新加载最新的模型参数和优化器的参数 ,在这个基础上继续训练。
下面的代码中,每隔 5 个 epoch 就保存一次,保存的是一个 dict,包括模型参数、优化器的参数、epoch。然后在 epoch 大于 5 时,就break模拟训练意外终止。关键代码如下:
1 2 3 4 5 6 7 if (epoch+1 ) % checkpoint_interval == 0 :checkpoint = {"model_state_dict": net.state_dict(),checkpoint , path_checkpoint)
在 epoch 大于 5 时,就break模拟训练意外终止
1 2 3 if epoch > 5 :print ("训练意外中断..." )break
断点续训练的恢复代码如下:
1 2 3 4 5 6 7 8 9 10 path_checkpoint = "./checkpoint_4_epoch.pkl"checkpoint = torch.load (path_checkpoint)checkpoint ['model_state_dict' ])checkpoint ['optimizer_state_dict' ])checkpoint ['epoch' ]
需要注意的是,还要设置scheduler.last_epoch参数为保存的 epoch。模型训练的起始 epoch 也要修改为保存的 epoch。
Finetune 迁移学习:把在 source domain 任务上的学习到的模型应用到 target domain 的任务。
Finetune(微调) 就是一种迁移学习的方法。比如做人脸识别,可以把 ImageNet 看作 source domain,人脸数据集看作 target domain。通常来说 source domain 要比 target domain 大得多。可以利用 ImageNet 训练好的网络应用到人脸识别中。
对于一个模型,通常可以分为前面的 feature extractor (卷积层)和后面的 classifier,在 Finetune 时,通常不改变 feature extractor 的权值,也就是冻结卷积层;并且改变最后一个全连接层的输出来适应目标任务,训练后面 classifier 的权值,这就是 Finetune。通常 target domain 的数据比较小,不足以训练全部参数,容易导致过拟合,因此不改变 feature extractor 的权值。
Finetune 步骤如下:
获取预训练模型的参数
使用load_state_dict()把参数加载到模型中
修改输出层
固定 feature extractor 的参数。这部分通常有 2 种做法:
固定卷积层的预训练参数。可以设置requires_grad=False或者lr=0
可以通过params_group给 feature extractor 设置一个较小的学习率
下面微调 ResNet18,用于蜜蜂和蚂蚁图片的二分类。训练集每类数据各 120 张,验证集每类数据各 70 张图片。
数据下载地址:http://download.pytorch.org/tutorial/hymenoptera_data.zip
预训练好的模型参数下载地址:http://download.pytorch.org/models/resnet18-5c106cde.pth
网络代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 "" " 模型finetune方法 " "" import osimport numpy as npimport torchimport torch.nn as nnimport DataLoaderimport torchvision.transforms as transformsimport torch.optim as optimimport pyplot as pltimport AntsDatasetimport set_seedimport torchvision.models as modelsimport enviromentsBASEDIR = os.path.dirname(os.path.abspath(__file__))device = torch.device("cuda" if torch.cuda.is_available() else "cpu" )"use device :{}" .format(device))1 ) label_name = {"ants" : 0 , "bees" : 1 }MAX_EPOCH = 25 BATCH_SIZE = 16 LR = 0.001 log_interval = 10 val_interval = 1 classes = 2 start_epoch = -1 lr_decay_step = 7 data_dir = enviroments.hymenoptera_data_dirtrain_dir = os.path.join(data_dir, "train" )valid_dir = os.path.join(data_dir, "val" )norm_mean = [0.485 , 0.456 , 0.406 ]norm_std = [0.229 , 0.224 , 0.225 ]train_transform = transforms.Compose([224 ),valid_transform = transforms.Compose([256 ),224 ),train_data = AntsDataset(data_dir=train_dir, transform=train_transform) valid_data = AntsDataset(data_dir=valid_dir, transform=valid_transform) train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True) valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE) resnet18_ft = models.resnet18()flag = 1 if flag:path_pretrained_model = enviroments.resnet18_pathstate_dict_load = torch.load(path_pretrained_model)flag_m1 = 0 if flag_m1:in resnet18_ft.parameters():requires_grad = Falsenum_ftrs = resnet18_ft.fc.in_featuresfc = nn.Linear(num_ftrs, classes)criterion = nn.CrossEntropyLoss() flag = 0 if flag:fc_params_id = list(map (id, resnet18_ft.fc.parameters())) base_params = filter(lambda p: id(p) not in fc_params_id, resnet18_ft.parameters())optimizer = optim.SGD([{'params': base_params, 'lr': LR * 0.1 }, {'params': resnet18_ft.fc.parameters(), 'lr': LR}],momentum=0.9) else :optimizer = optim.SGD(resnet18_ft.parameters(), lr=LR, momentum=0.9) scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_decay_step, gamma=0.1) train_curve = list()valid_curve = list()in range(start_epoch + 1 , MAX_EPOCH):loss_mean = 0 .correct = 0 .total = 0 .in enumerate(train_loader):labels = datalabels = inputs.to(device), labels.to(device)outputs = resnet18_ft(inputs)loss = criterion(outputs, labels)predicted = torch.max(outputs.data, 1 )0 )predicted == labels).squeeze().cpu().sum().numpy()if (i+1 ) % log_interval == 0 :loss_mean = loss_mean / log_interval"Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}" .format(1 , len(train_loader), loss_mean, correct / total))loss_mean = 0 .if (epoch+1 ) % val_interval == 0 :correct_val = 0 .total_val = 0 .loss_val = 0 .with torch.no_grad():in enumerate(valid_loader):labels = datalabels = inputs.to(device), labels.to(device)outputs = resnet18_ft(inputs)loss = criterion(outputs, labels)predicted = torch.max(outputs.data, 1 )0 )predicted == labels).squeeze().cpu().sum().numpy()loss_val_mean = loss_val/len(valid_loader)"Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}" .format(1 , len(valid_loader), loss_val_mean, correct_val / total_val))train_x = range(len(train_curve))train_y = train_curvetrain_iters = len(train_loader)valid_x = np.arange(1 , len(valid_curve)+1 ) * train_iters*val_interval valid_y = valid_curvelabel='Train') label='Valid') loc='upper right')
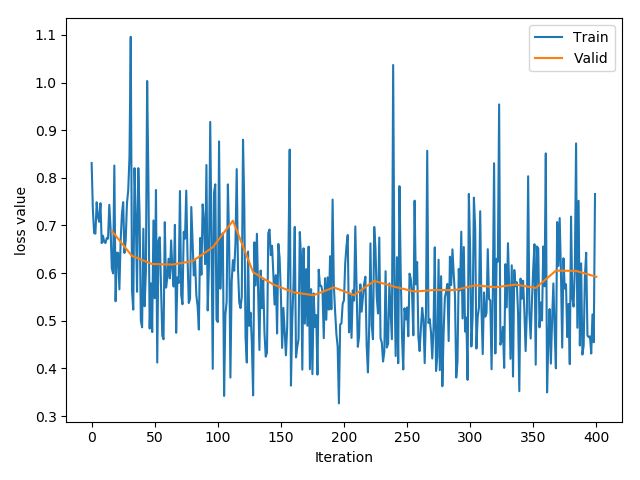
不使用 Finetune 第一次我们首先不使用 Finetune,而是从零开始训练模型,这时只需要修改全连接层即可:
1 2 3 4 num_ftrs = resnet18_ft.fc.in_featuresresnet18_ft.fc = nn.Linear(num_ftrs, classes)
输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 use device :cpuTraining :Epoch[000 /025 ] Iteration[010 /016 ] Loss: 0 .7192 Acc:47 .50 %Valid : Epoch[000 /025 ] Iteration[010 /010 ] Loss: 0 .6885 Acc:51 .63 %Training :Epoch[001 /025 ] Iteration[010 /016 ] Loss: 0 .6568 Acc:60 .62 %Valid : Epoch[001 /025 ] Iteration[010 /010 ] Loss: 0 .6360 Acc:59 .48 %Training :Epoch[002 /025 ] Iteration[010 /016 ] Loss: 0 .6411 Acc:60 .62 %Valid : Epoch[002 /025 ] Iteration[010 /010 ] Loss: 0 .6191 Acc:66 .01 %Training :Epoch[003 /025 ] Iteration[010 /016 ] Loss: 0 .5765 Acc:71 .25 %Valid : Epoch[003 /025 ] Iteration[010 /010 ] Loss: 0 .6179 Acc:67 .32 %Training :Epoch[004 /025 ] Iteration[010 /016 ] Loss: 0 .6074 Acc:67 .50 %Valid : Epoch[004 /025 ] Iteration[010 /010 ] Loss: 0 .6251 Acc:62 .75 %Training :Epoch[005 /025 ] Iteration[010 /016 ] Loss: 0 .6177 Acc:58 .75 %Valid : Epoch[005 /025 ] Iteration[010 /010 ] Loss: 0 .6541 Acc:64 .71 %Training :Epoch[006 /025 ] Iteration[010 /016 ] Loss: 0 .6103 Acc:65 .62 %Valid : Epoch[006 /025 ] Iteration[010 /010 ] Loss: 0 .7100 Acc:60 .78 %Training :Epoch[007 /025 ] Iteration[010 /016 ] Loss: 0 .6560 Acc:60 .62 %Valid : Epoch[007 /025 ] Iteration[010 /010 ] Loss: 0 .6019 Acc:67 .32 %Training :Epoch[008 /025 ] Iteration[010 /016 ] Loss: 0 .5454 Acc:70 .62 %Valid : Epoch[008 /025 ] Iteration[010 /010 ] Loss: 0 .5761 Acc:71 .90 %Training :Epoch[009 /025 ] Iteration[010 /016 ] Loss: 0 .5499 Acc:71 .25 %Valid : Epoch[009 /025 ] Iteration[010 /010 ] Loss: 0 .5598 Acc:71 .90 %Training :Epoch[010 /025 ] Iteration[010 /016 ] Loss: 0 .5466 Acc:69 .38 %Valid : Epoch[010 /025 ] Iteration[010 /010 ] Loss: 0 .5535 Acc:70 .59 %Training :Epoch[011 /025 ] Iteration[010 /016 ] Loss: 0 .5310 Acc:68 .12 %Valid : Epoch[011 /025 ] Iteration[010 /010 ] Loss: 0 .5700 Acc:70 .59 %Training :Epoch[012 /025 ] Iteration[010 /016 ] Loss: 0 .5024 Acc:72 .50 %Valid : Epoch[012 /025 ] Iteration[010 /010 ] Loss: 0 .5537 Acc:71 .90 %Training :Epoch[013 /025 ] Iteration[010 /016 ] Loss: 0 .5542 Acc:71 .25 %Valid : Epoch[013 /025 ] Iteration[010 /010 ] Loss: 0 .5836 Acc:71 .90 %Training :Epoch[014 /025 ] Iteration[010 /016 ] Loss: 0 .5458 Acc:71 .88 %Valid : Epoch[014 /025 ] Iteration[010 /010 ] Loss: 0 .5714 Acc:71 .24 %Training :Epoch[015 /025 ] Iteration[010 /016 ] Loss: 0 .5331 Acc:72 .50 %Valid : Epoch[015 /025 ] Iteration[010 /010 ] Loss: 0 .5613 Acc:73 .20 %Training :Epoch[016 /025 ] Iteration[010 /016 ] Loss: 0 .5296 Acc:71 .25 %Valid : Epoch[016 /025 ] Iteration[010 /010 ] Loss: 0 .5646 Acc:71 .24 %Training :Epoch[017 /025 ] Iteration[010 /016 ] Loss: 0 .5039 Acc:75 .00 %Valid : Epoch[017 /025 ] Iteration[010 /010 ] Loss: 0 .5643 Acc:71 .24 %Training :Epoch[018 /025 ] Iteration[010 /016 ] Loss: 0 .5351 Acc:73 .75 %Valid : Epoch[018 /025 ] Iteration[010 /010 ] Loss: 0 .5745 Acc:71 .24 %Training :Epoch[019 /025 ] Iteration[010 /016 ] Loss: 0 .5441 Acc:69 .38 %Valid : Epoch[019 /025 ] Iteration[010 /010 ] Loss: 0 .5703 Acc:71 .90 %Training :Epoch[020 /025 ] Iteration[010 /016 ] Loss: 0 .5582 Acc:69 .38 %Valid : Epoch[020 /025 ] Iteration[010 /010 ] Loss: 0 .5759 Acc:71 .90 %Training :Epoch[021 /025 ] Iteration[010 /016 ] Loss: 0 .5219 Acc:73 .75 %Valid : Epoch[021 /025 ] Iteration[010 /010 ] Loss: 0 .5689 Acc:72 .55 %Training :Epoch[022 /025 ] Iteration[010 /016 ] Loss: 0 .5670 Acc:70 .62 %Valid : Epoch[022 /025 ] Iteration[010 /010 ] Loss: 0 .6052 Acc:69 .28 %Training :Epoch[023 /025 ] Iteration[010 /016 ] Loss: 0 .5725 Acc:65 .62 %Valid : Epoch[023 /025 ] Iteration[010 /010 ] Loss: 0 .6047 Acc:68 .63 %Training :Epoch[024 /025 ] Iteration[010 /016 ] Loss: 0 .5761 Acc:66 .25 %Valid : Epoch[024 /025 ] Iteration[010 /010 ] Loss: 0 .5923 Acc:70 .59 %
训练了 25 个 epoch 后的准确率为:70.59%。
训练的 loss 曲线如下:
使用 Finetune 然后我们把下载的模型参数加载到模型中:
1 2 3 path_pretrained_model = enviroments.resnet18_path .load (path_pretrained_model).load_state_dict (state_dict_load)
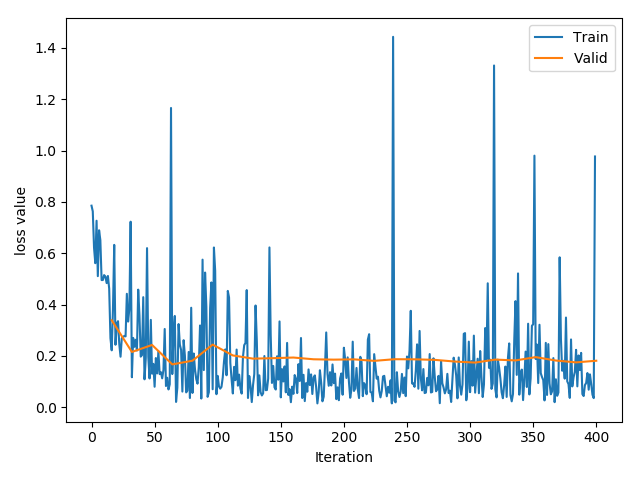
不冻结卷积层 这时我们不冻结卷积层,所有层都是用相同的学习率,输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 use device :cpuTraining :Epoch[000 /025 ] Iteration[010 /016 ] Loss: 0 .6299 Acc:65 .62 %Valid : Epoch[000 /025 ] Iteration[010 /010 ] Loss: 0 .3387 Acc:90 .20 %Training :Epoch[001 /025 ] Iteration[010 /016 ] Loss: 0 .3122 Acc:90 .00 %Valid : Epoch[001 /025 ] Iteration[010 /010 ] Loss: 0 .2150 Acc:94 .12 %Training :Epoch[002 /025 ] Iteration[010 /016 ] Loss: 0 .2748 Acc:85 .62 %Valid : Epoch[002 /025 ] Iteration[010 /010 ] Loss: 0 .2423 Acc:91 .50 %Training :Epoch[003 /025 ] Iteration[010 /016 ] Loss: 0 .1440 Acc:94 .38 %Valid : Epoch[003 /025 ] Iteration[010 /010 ] Loss: 0 .1666 Acc:95 .42 %Training :Epoch[004 /025 ] Iteration[010 /016 ] Loss: 0 .1983 Acc:92 .50 %Valid : Epoch[004 /025 ] Iteration[010 /010 ] Loss: 0 .1809 Acc:94 .77 %Training :Epoch[005 /025 ] Iteration[010 /016 ] Loss: 0 .1840 Acc:92 .50 %Valid : Epoch[005 /025 ] Iteration[010 /010 ] Loss: 0 .2437 Acc:91 .50 %Training :Epoch[006 /025 ] Iteration[010 /016 ] Loss: 0 .1921 Acc:93 .12 %Valid : Epoch[006 /025 ] Iteration[010 /010 ] Loss: 0 .2014 Acc:95 .42 %Training :Epoch[007 /025 ] Iteration[010 /016 ] Loss: 0 .1311 Acc:93 .12 %Valid : Epoch[007 /025 ] Iteration[010 /010 ] Loss: 0 .1890 Acc:96 .08 %Training :Epoch[008 /025 ] Iteration[010 /016 ] Loss: 0 .1395 Acc:94 .38 %Valid : Epoch[008 /025 ] Iteration[010 /010 ] Loss: 0 .1907 Acc:95 .42 %Training :Epoch[009 /025 ] Iteration[010 /016 ] Loss: 0 .1390 Acc:93 .75 %Valid : Epoch[009 /025 ] Iteration[010 /010 ] Loss: 0 .1933 Acc:95 .42 %Training :Epoch[010 /025 ] Iteration[010 /016 ] Loss: 0 .1065 Acc:96 .88 %Valid : Epoch[010 /025 ] Iteration[010 /010 ] Loss: 0 .1865 Acc:95 .42 %Training :Epoch[011 /025 ] Iteration[010 /016 ] Loss: 0 .0845 Acc:98 .12 %Valid : Epoch[011 /025 ] Iteration[010 /010 ] Loss: 0 .1851 Acc:96 .08 %Training :Epoch[012 /025 ] Iteration[010 /016 ] Loss: 0 .1068 Acc:95 .62 %Valid : Epoch[012 /025 ] Iteration[010 /010 ] Loss: 0 .1862 Acc:95 .42 %Training :Epoch[013 /025 ] Iteration[010 /016 ] Loss: 0 .0986 Acc:96 .25 %Valid : Epoch[013 /025 ] Iteration[010 /010 ] Loss: 0 .1803 Acc:96 .73 %Training :Epoch[014 /025 ] Iteration[010 /016 ] Loss: 0 .1083 Acc:96 .88 %Valid : Epoch[014 /025 ] Iteration[010 /010 ] Loss: 0 .1867 Acc:96 .08 %Training :Epoch[015 /025 ] Iteration[010 /016 ] Loss: 0 .0683 Acc:98 .12 %Valid : Epoch[015 /025 ] Iteration[010 /010 ] Loss: 0 .1863 Acc:95 .42 %Training :Epoch[016 /025 ] Iteration[010 /016 ] Loss: 0 .1271 Acc:96 .25 %Valid : Epoch[016 /025 ] Iteration[010 /010 ] Loss: 0 .1842 Acc:94 .77 %Training :Epoch[017 /025 ] Iteration[010 /016 ] Loss: 0 .0857 Acc:97 .50 %Valid : Epoch[017 /025 ] Iteration[010 /010 ] Loss: 0 .1776 Acc:96 .08 %Training :Epoch[018 /025 ] Iteration[010 /016 ] Loss: 0 .1338 Acc:94 .38 %Valid : Epoch[018 /025 ] Iteration[010 /010 ] Loss: 0 .1736 Acc:96 .08 %Training :Epoch[019 /025 ] Iteration[010 /016 ] Loss: 0 .1381 Acc:95 .62 %Valid : Epoch[019 /025 ] Iteration[010 /010 ] Loss: 0 .1852 Acc:93 .46 %Training :Epoch[020 /025 ] Iteration[010 /016 ] Loss: 0 .0936 Acc:96 .25 %Valid : Epoch[020 /025 ] Iteration[010 /010 ] Loss: 0 .1820 Acc:95 .42 %Training :Epoch[021 /025 ] Iteration[010 /016 ] Loss: 0 .1818 Acc:93 .75 %Valid : Epoch[021 /025 ] Iteration[010 /010 ] Loss: 0 .1949 Acc:92 .81 %Training :Epoch[022 /025 ] Iteration[010 /016 ] Loss: 0 .1525 Acc:93 .75 %Valid : Epoch[022 /025 ] Iteration[010 /010 ] Loss: 0 .1816 Acc:95 .42 %Training :Epoch[023 /025 ] Iteration[010 /016 ] Loss: 0 .1942 Acc:93 .12 %Valid : Epoch[023 /025 ] Iteration[010 /010 ] Loss: 0 .1744 Acc:96 .08 %Training :Epoch[024 /025 ] Iteration[010 /016 ] Loss: 0 .1268 Acc:96 .25 %Valid : Epoch[024 /025 ] Iteration[010 /010 ] Loss: 0 .1808 Acc:96 .08 %
训练了 25 个 epoch 后的准确率为:96.08%。
训练的 loss 曲线如下:
冻结卷积层 设置requires_grad=False 这里先冻结所有参数,然后再替换全连接层,相当于冻结了卷积层的参数:
1 2 3 4 5 6 for param in resnet18_ft.parameters():requires_grad = Falsenum_ftrs = resnet18_ft.fc.in_featuresfc = nn.Linear(num_ftrs, classes)
这里不提供实验结果。
设置学习率为 0 这里把卷积层的学习率设置为 0,需要在优化器里设置不同的学习率。首先获取全连接层参数的地址,然后使用 filter 过滤不属于全连接层的参数,也就是保留卷积层的参数;接着设置优化器的分组学习率,传入一个 list,包含 2 个元素,每个元素是字典,对应 2 个参数组。其中卷积层的学习率设置为 全连接层的 0.1 倍。
1 2 3 4 5 6 fc_params_id = list(map(id, resnet18_ft.fc.parameters())) base_params = filter(lambda p: id(p) not in fc_params_id, resnet18_ft.parameters())optimizer = optim.SGD([{'params' : base_params, 'lr' : 0 }, {'params' : resnet18_ft.fc.parameters(), 'lr' : LR}], momentum=0.9 )
这里不提供实验结果。
使用分组学习率 这里不冻结卷积层,而是对卷积层使用较小的学习率,对全连接层使用较大的学习率,需要在优化器里设置不同的学习率。首先获取全连接层参数的地址,然后使用 filter 过滤不属于全连接层的参数,也就是保留卷积层的参数;接着设置优化器的分组学习率,传入一个 list,包含 2 个元素,每个元素是字典,对应 2 个参数组。其中卷积层的学习率设置为 全连接层的 0.1 倍。
1 2 3 4 5 6 fc_params_id = list(map(id, resnet18_ft.fc.parameters())) base_params = filter(lambda p: id(p) not in fc_params_id, resnet18_ft.parameters())optimizer = optim.SGD([{'params' : base_params, 'lr' : LR*0 }, {'params' : resnet18_ft.fc.parameters(), 'lr' : LR}], momentum=0.9 )
这里不提供实验结果。
使用 GPU 训练模型 PyTorch 模型使用 GPU,可以分为 3 步:
首先获取 device:device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
把模型加载到 device:model.to(device)
在 data_loader 取数据的循环中,把每个 mini-batch 的数据和 label 加载到 device:inputs, labels = inputs.to(device), labels.to(device)
在数据运算时,两个数据进行运算,那么它们必须同时存放在同一个设备,要么同时是 CPU,要么同时是 GPU。而且数据和模型都要在同一个设备上。数据和模型可以使用to()方法从一个设备转移到另一个设备。而数据的to()方法还可以转换数据类型。
下面的代码是转换数据类型
1 2 x = torch.on es((3 ,3 ))x = x.to(torch.float64)
tensor.to() 和 module.to()首先导入库,获取 GPU 的 device
1 2 3 import torchimport torch.nn as nndevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu" )
下面的代码是执行Tensor的to()方法
1 2 3 4 5 x_cpu = torch.ones ((3 , 3 ))print ("x_cpu:\ndevice: {} is_cuda: {} id: {}" .format(x_cpu.device, x_cpu.is_cuda, id(x_cpu) .to (device)print ("x_gpu:\ndevice: {} is_cuda: {} id: {}" .format(x_gpu.device, x_gpu.is_cuda, id(x_gpu)
输出如下:
1 2 3 4 x_cpu: device: cpu is_cuda: False id: 1415020820304 x_gpu: device: cpu is_cuda: True id: 2700061800153
可以看到Tensor的to()方法不是 inplace 操作,x_cpu和x_gpu的内存地址不一样。
下面代码执行的是Module的to()方法
1 2 3 4 5 6 net = nn.Sequential (nn.Linear (3 , 3 ))print ("\nid:{} is_cuda: {}" .format(id(net) .parameters ()).is_cuda)).to (device)print ("\nid:{} is_cuda: {}" .format(id(net) .parameters ()).is_cuda))
输出如下:
1 2 id :2325748158192 is_cuda: False id :2325748158192 is_cuda: True
可以看到Module的to()方法是 inplace 操作,内存地址一样。
torch.cuda常用方法
torch.cuda.device_count():返回当前可见可用的 GPU 数量
torch.cuda.get_device_name():获取 GPU 名称
torch.cuda.manual_seed():为当前 GPU 设置随机种子
torch.cuda.manual_seed_all():为所有可见 GPU 设置随机种子
torch.cuda.set_device():设置主 GPU 为哪一个物理 GPU,此方法不推荐使用
os.environ.setdefault(“CUDA_VISIBLE_DEVICES”, “2”, “3”):设置可见 GPU
在 PyTorch 中,有物理 GPU 可以逻辑 GPU 之分,可以设置它们之间的对应关系。
os.environ.setdefault("CUDA_VISIBLE_DEVICES", "2", "3"),那么可见 GPU 数量只有 2 个。对应关系如下:
逻辑 GPU
物理 GPU
gpu0
gpu2
gpu1
gpu3
如果执行了os.environ.setdefault("CUDA_VISIBLE_DEVICES", "0", "3", "2"),那么可见 GPU 数量只有 3 个。对应关系如下:
逻辑 GPU
物理 GPU
gpu0
gpu0
gpu1
gpu3
gpu2
gpu2
设置的原因是可能系统中有很多用户和任务在使用 GPU,设置 GPU 编号,可以合理分配 GPU。通常默认gpu0为主 GPU。主 GPU 的概念与多 GPU 的分发并行机制有关。
多 GPU 的分发并行 1 torch.nn.DataParallel(module, device_ids =None, output_device =None, dim =0)
功能:包装模型,实现分发并行机制。可以把数据平均分发到各个 GPU 上,每个 GPU 实际的数据量为 $\frac{batch_size}{GPU 数量}$,实现并行计算。
主要参数:
module:需要包装分发的模型
device_ids:可分发的 GPU,默认分发到所有可见可用的 GPU
output_device:结果输出设备
需要注意的是:使用 DataParallel 时,device 要指定某个 GPU 为 主 GPU,否则会报错:
1 RuntimeError : module must have its parameters and buffers on device cuda:1 (device_ids[0 ]) but found one of them on device: cuda:2
这是因为,使用多 GPU 需要有一个主 GPU,来把每个 batch 的数据分发到每个 GPU,并从每个 GPU 收集计算好的结果。如果不指定主 GPU,那么数据就直接分发到每个 GPU,会造成有些数据在某个 GPU,而另一部分数据在其他 GPU,计算出错。
详情请参考 [RuntimeError: module must have its parameters and buffers on device cuda:1 (device_ids[0]) but found one of them on device: cuda:2 ](RuntimeError: module must have its parameters and buffers on device cuda:1 (device_ids[0]) but found one of them on device: cuda:2 )
下面的代码设置两个可见 GPU,batch_size 为 2,那么每个 GPU 每个 batch 拿到的数据数量为 8,在模型的前向传播中打印数据的数量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 ',' .join(map(str, gpu_list))"CUDA_VISIBLE_DEVICES" , gpu_list_str)"cuda:0" if torch.cuda.is_available() else "cpu" )to (device), labels.to (device)neural_num =3, layers =3)to (device)for epoch in range(1):print ("model outputs.size: {}" .format(outputs.size()))print ("CUDA_VISIBLE_DEVICES :{}" .format(os.environ["CUDA_VISIBLE_DEVICES" ]))print ("device_count :{}" .format(torch.cuda.device_count()))
输出如下:
1 2 3 4 batch size in forward: 8 model outputs.size: torch.Size([16 , 3 ])CUDA_VISIBLE_DEVICES :0 ,1 device_count :2
下面的代码是根据 GPU 剩余内存来排序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def get_gpu_memory():'Windows' != platform.system ():system ('nvidia-smi -q -d Memory | grep -A4 GPU | grep Free > tmp.txt' )int (x.split ()[2 ]) for x in open ('tmp.txt' , 'r' ).readlines ()]system ('rm tmp.txt' )print ("显存计算功能暂不支持windows操作系统" )get_gpu_memory ()print ("\ngpu free memory: {}" .format (gpu_memory))argsort (gpu_memory)[::-1 ]',' .join (map (str, gpu_list))setdefault ("CUDA_VISIBLE_DEVICES" , gpu_list_str)device ("cuda" if torch.cuda.is_available () else "cpu" )
其中nvidia-smi -q -d Memory是查询所有 GPU 的内存信息,-q表示查询,-d是指定查询的内容。
nvidia-smi -q -d Memory | grep -A4 GPU是截取 GPU 开始的 4 行,如下:
1 2 3 4 5 6 7 8 9 10 11 12 Attached GPUs : 2 FB Memory Usage Total : 24220 MiB Used : 845 MiB Free : 23375 MiB -- FB Memory Usage Total : 24217 MiB Used : 50 MiB Free : 24167 MiB
nvidia-smi -q -d Memory | grep -A4 GPU | grep Free是提取Free所在的行,也就是提取剩余内存的信息,如下:
1 2 Free : 23375 MiB MiB
nvidia-smi -q -d Memory | grep -A4 GPU | grep Free > tmp.txt是把剩余内存的信息保存到tmp.txt中。
[int(x.split()[2]) for x in open('tmp.txt', 'r').readlines()]是用列表表达式对每行进行处理。
假设x=" Free : 23375 MiB",那么x.split()默认以空格分割,结果是:
1 ['Free ', ': ', '23375 ', 'MiB ']
x.split()[2]的结果是23375。
假设gpu_memory=['5','9','3'],np.argsort(gpu_memory)的结果是array([2, 0, 1], dtype=int64),是从小到大取排好序后的索引。np.argsort(gpu_memory)[::-1]的结果是array([1, 0, 2], dtype=int64),也就是把元素的顺序反过来。
在 Python 中,list[<start>:<stop>:<step>]表示从start到stop取出元素,间隔为step,step=-1表示从stop到start取出元素。start默认为第一个元素的位置,stop默认为最后一个元素的位置。
','.join(map(str, gpu_list))的结果是'1,0,2'。
最后os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str)就是根据 GPU 剩余内存从大到小设置对应关系,这样默认最大剩余内存的 GPU 为主 GPU。
提高 GPU 的利用率 nvidia-smi命令查看可以 GPU 的利用率,如下图所示。
上半部分显示的是显卡的信息 ,下半部分显示的是每张显卡运行的进程 。可以看到编号为 0 的 GPU 运行的是 PID 为 14383 进程。Memory Usage表示显存的使用率,编号为 0 的 GPU 使用了 16555 MB 显存,显存的利用率大概是70% 左右。Volatile GPU-Util表示计算 GPU 实际运算能力的利用率,编号为 0 的 GPU 只有 27% 的使用率。
虽然使用 GPU 可以加速训练模型,但是如果GPU 的 Memory Usage 和 Volatile GPU-Util 太低,表示并没有充分利用 GPU。
因此,使用 GPU 训练模型,需要尽量提高 GPU 的 Memory Usage 和 Volatile GPU-Util 这两个指标,可以更进一步加速你的训练过程。
下面谈谈如何提高这两个指标。
Memory Usage 这个指标是由数据量主要是由模型大小,以及数据量的大小决定的。
模型大小是由网络的参数和网络结构决定的,模型越大,训练反而越慢。
我们主要调整的是每个 batch 训练的数据量的大小,也就是 batch_size 。
在模型结构固定的情况下,尽量将batch size设置得比较大,充分利用 GPU 的内存。
Volatile GPU-Util 上面设置比较大的 batch size可以提高 GPU 的内存使用率,却不一定能提高 GPU 运算单元的使用率。
从前面可以看到,我们的数据首先读取到 CPU 中的,并在循环训练的时候,通过tensor.to()方法从 CPU 加载到 CPU 中,如下代码所示。
1 2 3 4 5 6 7 8 # 遍历 train_loader 取数据 for i, data in enumerate(train_loader ):data CPU 加载到 GPU CPU 加载到 GPU
如果batch size得比较大,那么在 Dataset和 DataLoader ,CPU 处理一个 batch 的数据就会很慢,这时你会发现Volatile GPU-Util的值会在 0%,20%,70%,95%,0% 之间不断变化。
nvidia-smi命令查看可以 GPU 的利用率,但不能动态刷新显示。如果你想每隔一秒刷新显示 GPU 信息,可以使用watch -n 1 nvidia-smi 。
其实这是因为 GPU 处理数据非常快,而 CPU 处理数据较慢。GPU 每接收到一个 batch 的数据,使用率就跳到逐渐升高,处理完这个 batch 的数据后,使用率又逐渐降低,等到 CPU 把下一个 batch 的数据传过来。
解决方法是:设置 Dataloader的两个参数:
num_workers:默认只使用一个 CPU 读取和处理数据。可以设置为 4、8、16 等参数。但线程数并不是越大越好 。因为,多核处理需要把数据分发到每个 CPU,处理完成后需要从多个 CPU 收集数据,这个过程也是需要时间的。如果设置num_workers过大,分发和收集数据等操作占用了太多时间,反而会降低效率。
pin_memory:如果内存较大,建议设置为 True 。
设置为 True,表示把数据直接映射到 GPU 的相关内存块上,省掉了一点数据传输时间。
设置为 False,表示从 CPU 传入到缓存 RAM 里面,再给传输到 GPU 上。
GPU 相关的报错 1. 如果模型是在 GPU 上保存的,在无 GPU 设备上加载模型时torch.load(path_state_dict),会出现下面的报错:
1 RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False . If you are running on a CPU-only machine, please use torch.load with map_location=torch.device('cpu' ) to map your storages to the CPU.
可能的原因:gpu训练的模型保存后,在无gpu设备上无法直接加载。解决方法是设置map_location="cpu":torch.load(path_state_dict, map_location="cpu")
2. 如果模型经过net = nn.DataParallel(net)包装后,那么所有网络层的名称前面都会加上mmodule.。保存模型后再次加载时没有使用nn.DataParallel()包装,就会加载失败,因为state_dict中参数的名称对应不上。
1 2 3 Missing key (s) in state_dict: xxxxxxxxxxkey (s) in state_dict:xxxxxxxxxx
解决方法是加载参数后,遍历 state_dict 的参数,如果名字是以module.开头,则去掉module.。代码如下:
1 2 3 4 5 from collections import OrderedDictnew _state_dict = OrderedDict()for k, v in state_dict.items():7 :if k.startswith('module.' ) else knew _state_dict [namekey] = v
然后再把参数加载到模型中。
PyTorch常见报错汇总 请查看:https://shimo.im/docs/bdV4DBxQwUMLrfX5/read